
Smart Rollout: como o iFood utiliza Machine Learning para otimizar estratégias de marketing
Como o iFood usa machine learning e pesquisa operacional para otimizar a distribuição de cupons em escala massiva
Oferecer descontos ou cupons tornou-se uma estratégia natural de marketing para produtos digitais aumentarem métricas de negócio como compras ou engajamento dos usuários. No entanto, uma pergunta subsequente que esses negócios precisam responder é: qual desconto devem ser oferecidos, para quem e quando?
Embora isso possa parecer simples, uma única alocação de cupons tem impactos enormes nos resultados do negócio e requer soluções de engenharia complexas para ser aplicada a milhões de usuários em escala.
Neste artigo, descrevemos como o iFood usa machine learning e pesquisa operacional para fornecer às equipes de negócio uma plataforma que maximiza métricas de negócio com base em um público-alvo e restrições de negócio. Antes de mais nada, vamos definir o problema que precisamos resolver.
O Problema: Alocação de Cupons
O que é o iFood? Em poucas palavras, o iFood é a maior plataforma de delivery do Brasil, operando em mais de 1.000 cidades e conectando usuários com restaurantes e mercados através de seus aplicativos móveis e web. Em novembro de 2025, alcançou a marca de 180 milhões de pedidos mensais. Com um número tão alto de pedidos, qualquer estratégia de distribuição de cupons desempenha um papel crítico na manutenção tanto do engajamento dos usuários quanto da rentabilidade do negócio.
Definindo uma Estratégia de Distribuição de Cupons
No iFood, definimos uma estratégia de alocação usando 4 pilares:
- – Público: um público-alvo que receberá os cupons. Podem ser usuários em churn, novos usuários ou até assinantes.
- – Indicador-Chave de Performance (KPI): qual métrica de negócio queremos melhorar, como maximizar pedidos, maximizar receita ou minimizar custos.
- – Portfólio de cupons: um conjunto de diferentes cupons que os usuários dentro do público podem receber. Podemos ter R$5,00 de desconto no valor do carrinho, 10% de desconto em itens específicos ou entrega grátis e muitos outros tipos de mecânicas de cupom.
- – Restrições de negócio: regras específicas que a alocação deve seguir, como um orçamento máximo em incentivos.
Todos esses 4 componentes são definidos pelas equipes de negócio com base em suas demandas específicas, que variam em áreas específicas do produto. Por exemplo, equipes que operam em unidades de mercado provavelmente terão configurações de otimização diferentes das unidades de entrega de comida.
Uma vez que uma estratégia de alocação foi definida, ela pode ser traduzida em um problema de otimização. Mas antes de fazer isso, precisamos fazer uma rápida viagem ao reino da economia.
Elasticidade de Preço
A elasticidade de preço mede o quanto uma mudança no preço afeta a demanda de um produto. Quando um item é elástico, uma mudança no preço resulta em uma mudança significativa nas vendas. Se uma mudança de preço cria uma mudança pequena ou nenhuma mudança nas vendas, então dizemos que o item é inelástico.
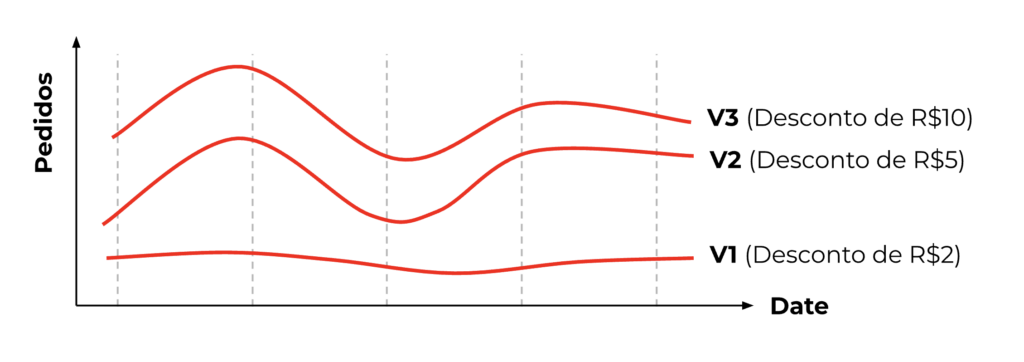
No contexto de fornecer descontos aos usuários, as curvas de elasticidade dizem o quão sensíveis os usuários são aos incentivos. Digamos que temos as seguintes variantes de incentivo:
- – V1: desconto de R$2
- – V2: desconto de R$5
- – V3: desconto de R$10
A maioria das pessoas pensaria que quanto maiores os incentivos, maior a taxa de conversão. No entanto, como dizemos no Brasil: a vida não é um morango! Nem todos os usuários reagem da mesma forma quando recebem incentivos. Na verdade, podemos operar em 3 tipos de ambientes:
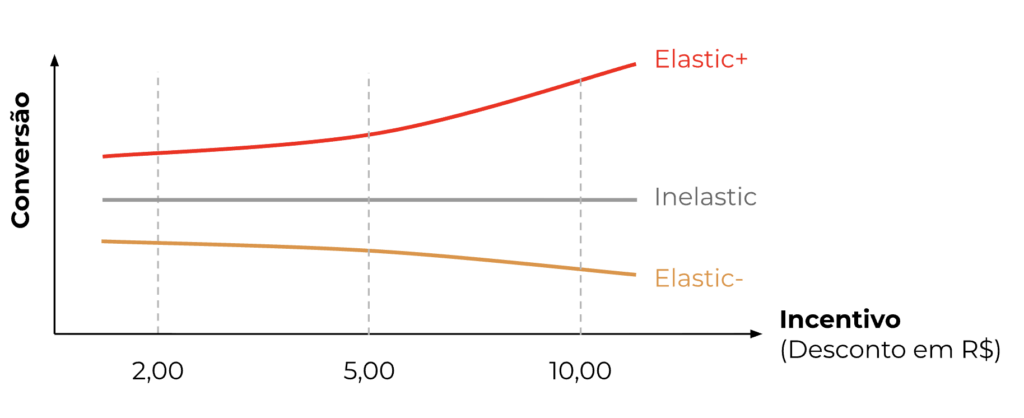
- – Elástico+: quanto maiores os incentivos, maior a taxa de conversão
- – Inelástico: sem resposta aos incentivos
- – Elástico-: quanto maiores os incentivos, menor a taxa de conversão
Dito isso, vamos avançar para nosso problema de otimização.
Definindo um Problema de Otimização
A maioria dos problemas de otimização se enquadra na seguinte estrutura:
Dado um conjunto de variáveis X, encontre os valores de X que maximizam uma função objetivo F restrita a um conjunto de restrições C. Ou, em termos matemáticos:
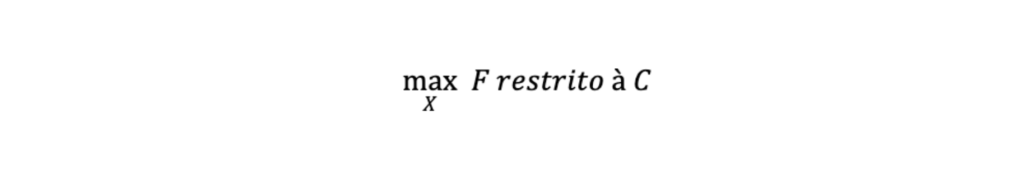
Vamos dividir isso em problemas mais simples e gradualmente torná-lo mais complexo. Considere o conjunto previamente definido de variantes de cupom V (v1, v2 e v3) e um conjunto de variáveis de decisão X(x1, x2 e x3) que decide a fração de usuários que receberá cada uma dessas variantes.
Problema 1: Maximizar Pedidos
Como a variável X representa uma fração, cada um de seus valores deve somar 100%. Assim, é traduzida como uma restrição de alocação Ca para nosso problema de otimização:
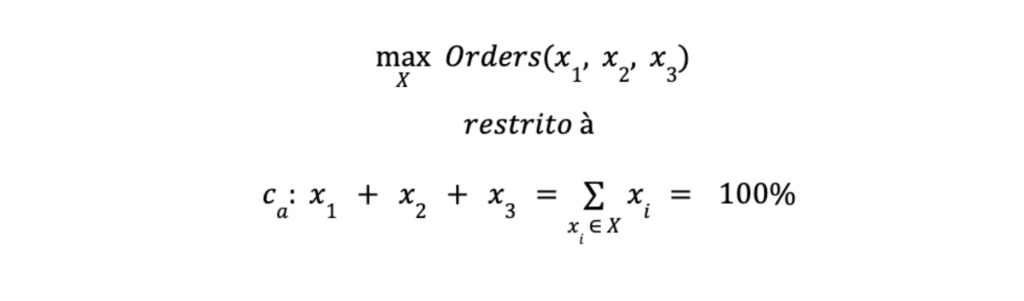
Em seguida, precisamos definir a função objetivo Orders em termos de nossas variáveis de decisão x1, x2 e x3.
Para fazer isso, olhamos para dados históricos e estimamos quantos pedidos essas variantes de cupom gerariam se operassem separadamente. Por exemplo, em um determinado público, podemos inferir de dados históricos que a variante v1 forneceria ô1 = 40 pedidos quando x1 = 100%. Alternativamente, inferimos que ô2 = 70 pedidos e ô3 = 150 pedidos para v2 e v3, respectivamente. Basicamente, estamos estimando as curvas de elasticidade de preço.
Com base nesses valores oi, podemos assumir que se alocássemos uma fração xi de usuários na variante vi, obteríamos xi oi pedidos, o que leva à função objetivo que faltava:
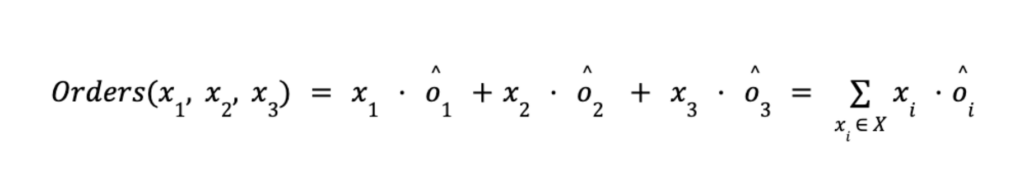
Finalmente, definimos o problema de otimização completo:
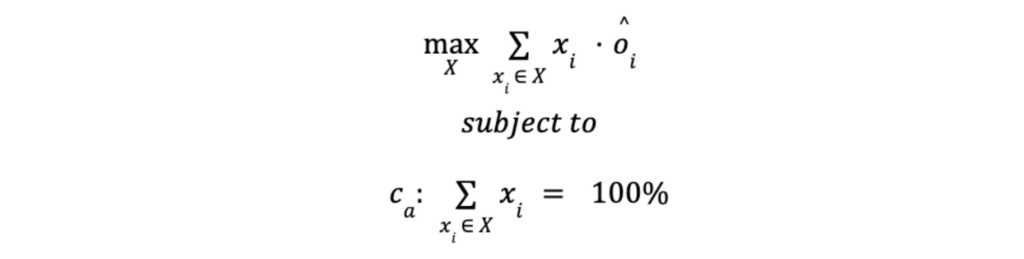
Problema 2: Maximizar Pedidos, mantendo no máximo um desconto médio de R$ 4 por pedido
Agora, além da restrição de alocação, a equipe de negócios solicitou que o iFood dê, em média, um desconto de R$4 no máximo.
Dado que as variantes v1, v2 e v3 representam descontos de R$2, R$5 e R$10, respectivamente, podemos traduzir essa solicitação em uma restrição de orçamento adicional Cb:
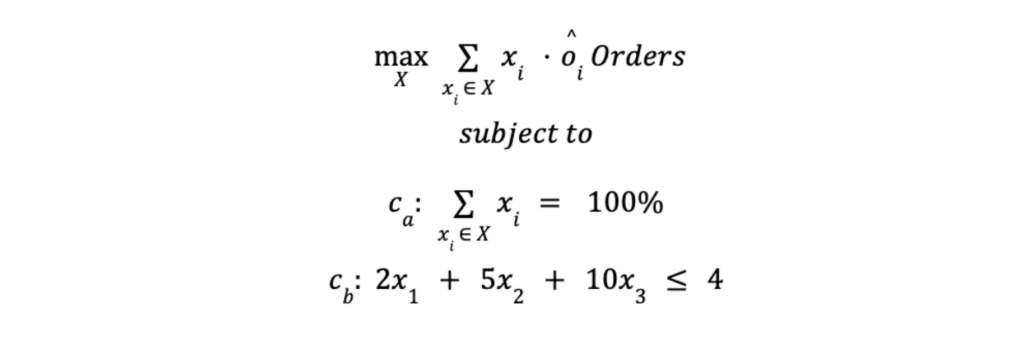
Uma vez que temos o problema de otimização definido, precisamos implementar um algoritmo que o resolva com base em dados históricos.
A Solução: Prever e Otimizar
O problema de otimização é uma abstração do framework Prever + Otimizar, que envolve duas etapas principais:
- – Prever: Fazer previsões sobre as métricas necessárias (por exemplo, pedidos previstos para cada variante de cupom).
- – Otimizar: Tomar decisões de alocação com base nas métricas inferidas para maximizar a função objetivo enquanto atende às restrições.
Com base no problema de otimização apresentado, precisamos fazer previsões sobre os pedidos considerando cada variante de cupom.
Digamos que estamos tomando decisões diariamente, ou seja, todos os dias mudamos a distribuição de cupons. Então, as previsões podem ser feitas buscando uma série temporal histórica para cada uma das variantes e estimando cada métrica para o próximo dia.
A previsão de séries temporais é um desafio em si e muitos algoritmos foram desenvolvidos neste campo. A maioria dos algoritmos depende apenas de dados passados, caso em que a função de previsão seria algo como:
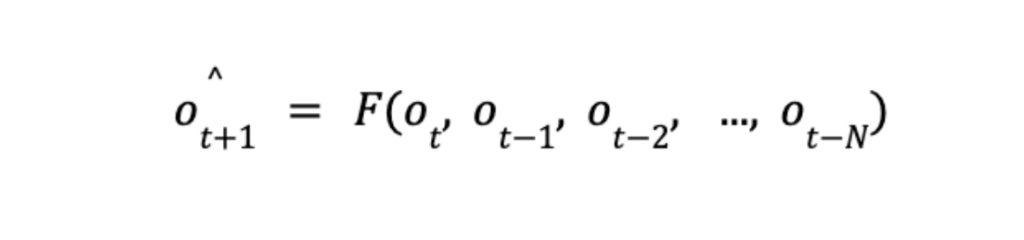
onde N é o número de pontos de dados passados a considerar e “o_t” é o valor da métrica no dia t. Um dos algoritmos mais simples que se pode usar é a Média Móvel Ponderada Exponencial, que faz previsões calculando a média de dados passados em uma determinada janela de tempo e ponderando os dados de acordo com sua recência.
Uma vez que os modelos de inferência são treinados e as previsões são computadas, pode-se usar vários algoritmos de otimização como programação linear e programação linear mista, que estão disponíveis em bibliotecas python como PuLP ou SciPy.
Mais recentemente, usamos os Large Commerce Models do iFood como o motor principal para fazer essas inferências, o que melhorou muito nossa capacidade de inferência ao aproveitar o conhecimento contextual dos LLMs para superar problemas de cold-start, ou seja, quando não temos informações suficientes para criar séries temporais empíricas.
A Plataforma: Escalando para Múltiplos Negócios
Como você pode ver, muitas configurações diferentes podem ser definidas para uma única estratégia de alocação de cupons: o público a ser impactado, o portfólio de cupons a ser oferecido, as restrições de negócio a serem definidas e muitos outros parâmetros. Todos esses podem variar dependendo da unidade de negócio, e assim precisamos fornecer às diferentes equipes de operações uma arquitetura de solução robusta e escalável.
Para este fim, construímos os Smart Rollout Models, um framework capaz de abstrair todas essas configurações e soluções concisas em uma única biblioteca python.
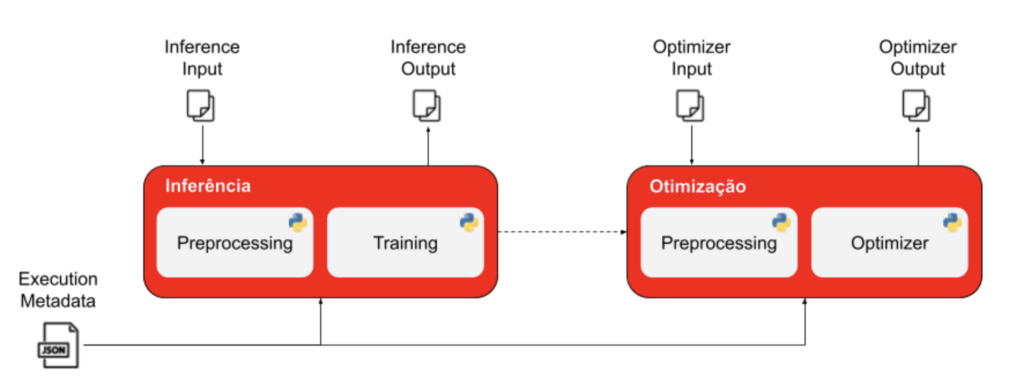
Ao definir metadados de execução para os módulos de inferência e otimização, a biblioteca orquestra o fluxo de trabalho e produz os resultados de alocação, que são então alimentados para serviços de engenharia externos responsáveis por servir os cupons em escala.
No início de janeiro de 2026, o framework processa:
- +60 estratégias com unidades de negócio variadas (entrega de comida, mercados, farmácia) e ciclos de vida de usuários (churn inicial, churn tardio, novos usuários, prospects)
- +300 variantes de cupom com mecânicas de cupom variadas (% de desconto, descontos, entrega grátis)
- +16.000 previsões de séries temporais com métricas variadas (pedidos, subsídio, valor bruto de mercadoria)
Conclusão
Neste artigo, apresentamos o “Smart Rollout” do iFood, uma plataforma projetada para otimizar a alocação de cupons em escala massiva. Demonstramos como machine learning e pesquisa operacional são combinados para resolver o desafio complexo de determinar qual desconto dar, para quem e quando, enquanto maximiza métricas-chave de negócio e adere a restrições rigorosas de negócio.
Ao definir uma estratégia de alocação baseada em quatro pilares-chave (Público, KPI, Portfólio de Cupons e Restrições de Negócio), traduzimos necessidades de negócio em um problema de otimização claro. O núcleo da solução reside no framework Prever + Otimizar, onde modelos de previsão de séries temporais preveem o desempenho esperado de várias variantes de cupom (Prever), e um algoritmo de otimização então determina a alocação ideal de usuários para maximizar a função objetivo (Otimizar).
Finalmente, o framework Smart Rollout Models abstrai esse fluxo de trabalho complexo em uma biblioteca Python escalável, atualmente gerenciando numerosas estratégias distintas, muitas variantes de cupom e milhares de previsões de séries temporais em várias unidades de negócio. Este sistema garante que a estratégia de incentivos do iFood seja orientada por dados, eficiente e altamente eficaz em impulsionar engajamento e rentabilidade.

Joao Felipe Guedes
Data Scientist
Engenheiro de Machine Learning no iFood desde 2024. É formado em Engenharia Eletrônica e de Computação pela Universidade Federal do Rio de Janeiro e possui mestrado em Inteligência Computacional pela Coppe/UFRJ.
Build the future at iFood
We are always looking for passionate developers, designers and data scientists to help us revolutionize the food delivery experience. Join iFood Tech and be part of building the future of food technology.
Discover our CareersYou might also like to read
Read more about Dados & IASmart Rollout: How iFood uses Machine Learning to optimize coupon allocation
How iFood uses machine learning and operational research to optimize coupon distribution at massive scale Providing discounts or coupons has become a natural marketing strategy for digital products to increase business metrics like purchases or user engagement. However, a follow-up…



How iFood’s generative AI connects personalization and communication through rigorous engineering patterns to scale unique user experiences
How iFood's generative AI connects personalization and communication through rigorous engineering patterns to scale unique user experiences From Grouped Campaigns to Individual Decisions [4:30 PM, Tuesday] Haven't had lunch yet, right? The Mushroom Risotto you love is waiting for you…



Yggdrasil: Scaling Authorization at iFood with Cedar and a Stateless Architecture
In a microservices ecosystem as dynamic and complex as iFood's, ensuring that people and systems have appropriate access to the right resources is a constant challenge. Historically, in most cases, authorization logic is implemented in a decentralized and inconsistent manner…

Meet other Authors
Each article is the result of the vision and expertise of our authors. See who contributes to our blog:























