
Rethinking Measurement: How our Proprietary MMM enhanced our Media perspective
Text written by Fernanda Borém, Senior Data Scientist and Mariane Bando, Data Science Coordinator of the MediaLab team.

Digital marketing lives a paradox: we’ve never had so much data and, at the same time, it has never been so difficult to isolate causal effects. Traditional attribution models capture direct conversions, but leave blind spots: branding campaigns, offline channels, long-term effects, awareness effects.
The fundamental question remains: how to confidently estimate the incremental impact of each channel and decide where to allocate the next million?
This is the account of how we built Bobyn, our proprietary MMM (Marketing Mix Model), and the platform that seeks to democratize marketing mix modeling at iFood.
The Problem: A Marketing Vision in the Dark
Before Bobyn, we had a classic causal inference problem: measuring the incremental gain of each marketing channel on business KPIs, performing investment simulations and optimizing budget allocation (whether for sessions, orders or other KPIs). The challenges were predictable, but not trivial:
- Limited data: Daily or weekly time series are short for complex models. How to estimate individual effects of 10+ channels with ~365 observations per year?
- Non-trackable channels: OOH (out-of-home) and branding campaigns don’t generate direct clicks or conversions. How to attribute value to them?
- External confounders: Holidays, seasonality, competitor actions, external events (Black Friday, World Cup). How to isolate the real effect of our investments?
- Media effects are not instantaneous: How to model temporal persistence of awareness and conversion?
- Channel saturation: Decreasing marginal returns are expected, but where is the inflection point for each channel?
Why not use something ready-made?
We tested well-known open-source tools (Robyn, Meridian) and consulted market solutions. The problem wasn’t their technical capacity – in fact, they are excellent – but our context (multiple verticals, varied KPIs, need for fine control) called for a more customized solution:
- Flexibility: We needed to quickly adapt the model for different verticals (food, groceries, pharma) and KPIs (sessions, orders, GMV)
- Interpretability: Business stakeholders needed to understand not only the results, but why the model suggested a certain allocation
- Full control: We wanted to iterate quickly, test different priors, add custom features without depending on external roadmap
- Internal knowledge: We already had a DS team capable of building and maintaining a custom Bayesian model
The choice became clear: building our own MMM would give us control, transparency and the ability to evolve the model alongside the business.
The Solution: Our Own Bayesian Model and a Self-Service Platform
With a well-calibrated MMM, we could answer questions that previously depended on intuition or A/B tests that were difficult or even impossible to perform, for example:
- What is the incremental impact and ROI of each channel (online and offline)?
- How to reallocate budget to maximize a specific metric (sessions, orders, GMV)?
- Where is the saturation point of each channel?
The solution involved two fronts: building a model that encompassed the modeling challenges and making it accessible to the entire company.
1. The Brain: Our Bayesian Model “Bobyn”
Building our own solution in Python, using libraries like PyMC, gave us full control. We opted for Bayesian modeling because it allowed us to go beyond cold numbers:
- Expert Knowledge in Code: We managed to translate business knowledge into mathematical assumptions (the model’s “priors”). With many channels and a leaner data base, Bayesian priors help regularize the model by incorporating domain knowledge, facilitating learning. Thus, we offer “hints” to the model, for example: TV ads have more prolonged effect than digital channels.
- Flexibility for the Real World: We modeled complex effects like saturation (the curve of decreasing returns) and carryover (the residual impact of a campaign over time), making predictions much more realistic.
- TV has more prolonged effect than search → smoother decay prior
- Digital saturates faster than OOH → more aggressive saturation prior
- Effects cannot be negative → LogNormal distribution
It’s important to note that our goal is not to bias arbitrarily — it’s to translate marketing knowledge into mathematics.
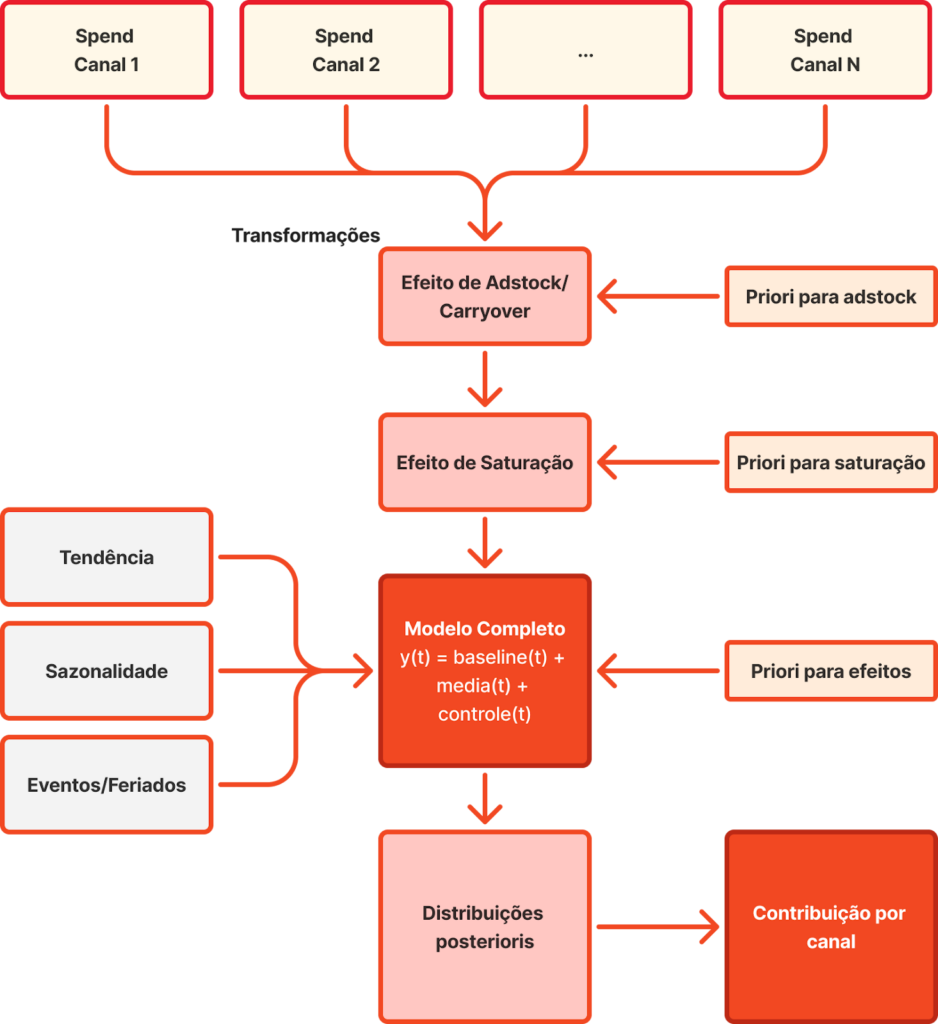
Simplified model structure:
$$ Y_t = baseline_t + Σ (saturation(adstock(spend_channel_i))) + effects_t $$
where:
- baseline_t = trend + seasonality + events
- adstock = temporal carryover (geometric decay)
- saturation = Hill transform (decreasing returns)
2. The Body: The Democratization Platform
A brilliant model in the hands of few has limited impact. That’s why we created an internal platform that allows any business analyst to create their own MMM simply and quickly, adding operational knowledge in a simple way.
What does the platform do?
- Democratizes access: Any area can create, run and interpret sophisticated models easily, in addition to configuring priors for prolonged effect and saturation.
- Integrates Bobyn: Our exclusive model is already integrated, ensuring quality and consistency of analyses.
- Allows simulating and optimizing the future: With the optimization and simulation tool, teams can answer questions like “what happens if…” and make smarter decisions about budget.
- Frees our Data Scientists: With the platform taking care of execution, our DS team can focus on what they do best: evolving the model and acting as strategic support.
- GenPlat as support for insights: Our LLM platform translates and summarizes insights, in addition to answering specific questions based on results.
Unplanned benefit
The platform simplifies model creation, but doesn’t eliminate the need for technical knowledge — and this is intentional. Whenever a new team shows interest, we seek to provide complete onboarding: we explain the methodology, where the numbers come from and how to interpret credibility intervals.
This process became an essential part of the product. We realized that confidence in results doesn’t come only from model accuracy, but from stakeholders understanding why the model suggests a certain allocation. The platform facilitates experimentation, but technical learning remains necessary — and desired.
The Impact: From Uncertainty to Strategic Decision
The result is a robust solution that is expanding throughout the company, far beyond the marketing team. It has become a strategic planning tool.
One of the project’s great supporters was the Branding team, which has been seeking to be increasingly Data-Driven to make investment decisions. Historically, the area has high investments in offline media, so the great pain point has always been: are we investing too much or too little? Furthermore, are we investing correctly?
Using our platform’s optimizer and scenario simulator, the team was able to get answers to these doubts, which allowed them to generate and test new budget allocations between channels, without compromising a single real from the plan.
The result? In September, the team managed to reduce investment by 2% – a very significant number in absolute terms – in some saturated channels while maintaining the total volume of sessions.
The Next Chapter of Measurement
Building Bobyn was challenging, but it was worth it. Having full control over the model means we can iterate quickly, add custom features and, most importantly, explain to stakeholders exactly where the recommendations come from.
And this is just the beginning. We’re already exploring the next challenges:
- Integration with experimentation
We are calibrating the MMM with geolift test results. The idea is to use incrementality measured via experiments to suggest prior distributions, creating a validation cycle between methodologies.
- Digital attribution as input
Over these past months, we also improved our attribution models (MTA), so the next step is to use the MTA model distributions to inform the priors of digital channels in the MMM. This approach is especially useful for channels with low volume of historical data.
Lessons learned:
Build vs buy is not binary: Tools like Robyn (Meta) and Meridian (Google) are excellent and solve well for many cases. But our context — multiple verticals (food, groceries, pharma), varied KPIs (sessions, orders, GMV, ROI), need to iterate quickly — called for deep customization.
- The decision was not “create everything from scratch”. We used PyMC-Marketing as a base and built on top of it. The real gain came from flexibility: when the CRM team asked to include push notifications as a “channel”, we adjusted the model in 2 weeks. With third-party tools, this would be a quarterly roadmap.
- Attention: open libraries require solid knowledge of Bayesian theory and the code base. It’s not “plug and play” — you need to understand what’s happening under the hood.
Interpretation > accuracy: Stakeholders trusted the model not only because it had good metrics, but because they understood the logic behind it. Transparency won over complexity.
It’s important to invest as much time in visualizations and explanations as in tuning priors. The contribution charts, saturation and interactive simulations generated more confidence than perfect model diagnostics.
Self-service has limits: The platform accelerated adoption, but technical onboarding remains essential. We don’t want to create poorly configured models, because that generates bad decisions.
About us
Nice to meet you, we are the MediaLab team at iFood! Our job is to build data tools that help media, branding and CRM teams make better decisions: from Bobyn (MMM) to LLM agents for hyper personalization of notifications.
If you work with marketing analytics, experimentation or Bayesian modeling and want to exchange ideas, reach out to us on LinkedIn or comment below!

Build the future at iFood
We are always looking for passionate developers, designers and data scientists to help us revolutionize the food delivery experience. Join iFood Tech and be part of building the future of food technology.
Discover our CareersYou might also like to read
Read more about Dados & IA
How iFood’s generative AI connects personalization and communication through rigorous engineering patterns to scale unique user experiences
How iFood's generative AI connects personalization and communication through rigorous engineering patterns to scale unique user experiences From Grouped Campaigns to Individual Decisions [4:30 PM, Tuesday] Haven't had lunch yet, right? The Mushroom Risotto you love is waiting for you…



Yggdrasil: Scaling Authorization at iFood with Cedar and a Stateless Architecture
In a microservices ecosystem as dynamic and complex as iFood's, ensuring that people and systems have appropriate access to the right resources is a constant challenge. Historically, in most cases, authorization logic is implemented in a decentralized and inconsistent manner…


How iFood Enhanced Feature Management to Combat Fraud
In this publication, we present how iFood benefited from using a Features Platform, which in addition to simplifying feature management, also provided a robust, efficient infrastructure and mitigated latency problems previously faced in fraud detection and combat. The digital revolution…

Meet other Authors
Each article is the result of the vision and expertise of our authors. See who contributes to our blog:





















