
Auto Approval: como o iFood acelerou a revisão de código em 33% com avaliação automática de risco
Da fila de MRs à análise de risco automatizada: como contexto, heurísticas e LLMs revolucionaram o code review no iFood
No iFood, acelerar o processo de engenharia sem abrir mão de segurança e qualidade é um desafio constante, especialmente quando levamos em consideração a escala dos nossos serviços.
Com mais de 1.500 pessoas engenheiras, cerca de 10 mil repositórios e dezenas de milhares de merge requests (MRs) circulando todos os meses, qualquer etapa que vire fila rapidamente deixa de ser um detalhe operacional e passa a impactar a experiência de desenvolvimento como um todo. Foi olhando para esse cenário que o time de Developer Experience identificou um gargalo importante: o tempo de espera no code review.
A partir daí surgiu o Auto Approval, um sistema que usa IA para avaliar o risco de mudanças pequenas em código e, quando elas são consideradas seguras, aprová-las automaticamente. O resultado da implementação do novo sistema foi uma redução de cerca de 33% no tempo global de aprovação de merge requests e uma queda de aproximadamente 58% no tempo de aprovação de MRs com menos de 30 linhas.
Para além de apenas automatizar uma etapa, o projeto buscava acelerar o fluxo de desenvolvimento sem aumentar os riscos envolvidos.
Quando o problema não é revisar código, e sim esperar pela revisão
O time de Developer Experience atua para que quem desenvolve tenha a melhor experiência possível, priorizando a produtividade. Isso envolve desde gerenciar pipelines e automações até cuidar de padrões, quality tooling e do desenvolvimento de novos agentes internos.
Ao medir diferentes etapas do ciclo de desenvolvimento, o time percebeu que o processo de code review consumia mais tempo do que deveria. No recorte apresentado, o iFood lidava com algo em torno de 18 mil merge requests por mês, e a cauda desse processo era especialmente pesada: o tempo de aprovação chegava a 65 horas, enquanto o tempo de merge batia 96 horas.
Mas o dado mais revelador veio logo depois. Quase metade dos MRs analisados, 48%, tinha menos de 30 linhas de mudanças. Ou seja: uma parte enorme do volume total era composta por alterações simples, mas que frequentemente entravam na mesma fila das mudanças mais complexas.
Na prática, isso significava que ajustes pequenos (como mudanças pontuais de interface, documentação ou correções localizadas) podiam levar horas para receber uma aprovação, não porque fossem difíceis de revisar, mas porque o time de engenharia de software estava ocupado com outras prioridades.
Foi aí que o problema começou a ser reformulado.
Reduzir o problema
Uma revisão de código envolve muitas dimensões simultâneas. Estilo, organização, performance, aderência a padrões internos, contexto de negócio e segurança, por exemplo. Deixar para um LLM decidir tudo isso de uma vez aumentaria muito a chance de erro, especialmente em um fluxo no qual um falso positivo (ou seja, onde o modelo classificou um MR como aprovado quando não deveria) é caro demais.
Então o time escolheu não tentar automatizar o processo de code review em si, por completo.
Ao invés disso, o Auto Approval atua avaliando o risco representado por cada mudança. Essa lógica aparece explicitamente na formulação técnica da solução, que transforma o problema (análogo à redução de problemas computacionais, em teoria de análise de algoritmos) amplo de aprovação de mudanças de código em uma decisão sobre o risco do diff submetido
Submeter um prompt como “este código deveria ser aprovado?” sem especificações de como fazer essa análise pode englobar vários sentidos implícitos subjetivos como: “esse código está seguindo o estilo padronizado do repositório?”, “está corretamente estruturado?” ou “é a implementação mais otimizada possível?”. Isso eleva a probabilidade de classificações incorretas a respeito da aprovação de um diff. Já com um prompt como “essa mudança representa um risco real para o sistema?”, a avaliação fica muito mais objetiva e alinhada ao que realmente importa para os fluxos.
A decisão ficou assim: se o risco for baixo o suficiente, o MR pode ser aprovado automaticamente e o autor pode fazer o merge. Se não for, o processo segue normalmente para a revisão humana.
Tirar a fricção de onde ela não precisa estar
O nome pode sugerir uma autonomia maior do que de fato existe, então vale esclarecer: o sistema aprova o merge request, mas não o faz automaticamente. Depois da aprovação, a pessoa autora da mudança ainda decide se quer seguir com o merge, pedir revisão adicional ou seguir o fluxo usual. Se a mudança não for aprovada pelo sistema, nada trava: o MR segue normalmente para a etapa de revisão por pares.
Isso foi importante para posicionar a ferramenta como um acelerador, e não como um substituto absoluto da revisão humana.
Na prática, o ganho aparece em momentos muito concretos. Um bugfix simples fora do horário comercial, uma alteração pequena que precisava entrar rápido, ou um ajuste operacional que não precisava ficar parado por horas na fila. Em todos esses casos, o Auto Approval reduz o tempo entre fazer a solicitação e poder seguir com o merge de fato.
Como o sistema funciona na prática
O Auto Approval escuta eventos do GitLab. Quando um novo merge request é criado, ele inicia uma sequência de avaliação que combina elegibilidade, análise estática e análise com IA.
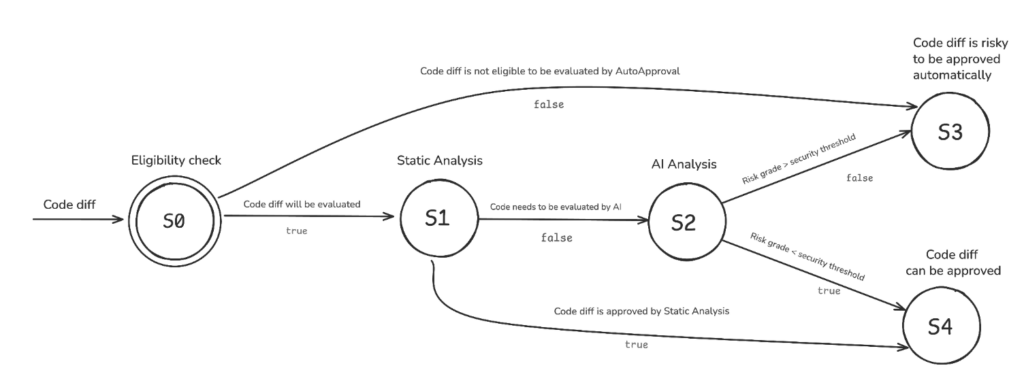
1. Checagem de elegibilidade
Antes de qualquer análise do diff, o sistema verifica se aquele MR pode entrar no fluxo.
Alguns repositórios ficam fora do escopo por definição, como sistemas muito sensíveis (sistemas financeiros, por exemplo) em que a tolerância a risco precisa ser praticamente nula. Além disso, o Auto Approval só opera sobre mudanças pequenas: se o diff ultrapassar 30 linhas de código-fonte alteradas, ele nem segue para a etapa de IA.
2. Análise estática e heurística
Se o MR é elegível, o sistema ainda passa por uma camada de regras simples. Mudanças em arquivos não sensíveis, documentação, texto ou certos tipos de configuração podem ser aprovadas nessa etapa, sem necessidade de enviar o caso para o modelo.
A análise estática também conta com um allow-list de repositórios que não precisam de revisão de código.
3. Análise de risco com IA
Quando o MR precisa de análise mais profunda, o sistema envia para o modelo não apenas o diff, mas também um conjunto de contextos adicionais: arquivos-base, título e descrição do merge request, estrutura do repositório, README e file map. A ideia é dar ao modelo contexto suficiente para entender o que mudou, onde mudou e qual o papel daquele código dentro do projeto.
A resposta é formatada com structured outputs, seguindo um schema definido pelo sistema: uma nota de risco entre 0.1 e 1.0, uma justificativa detalhada e um resumo. Se a nota for de 0.4 ou menos, o MR é aprovado automaticamente. Acima disso, não há aprovação automática e a revisão humana será a próxima etapa.
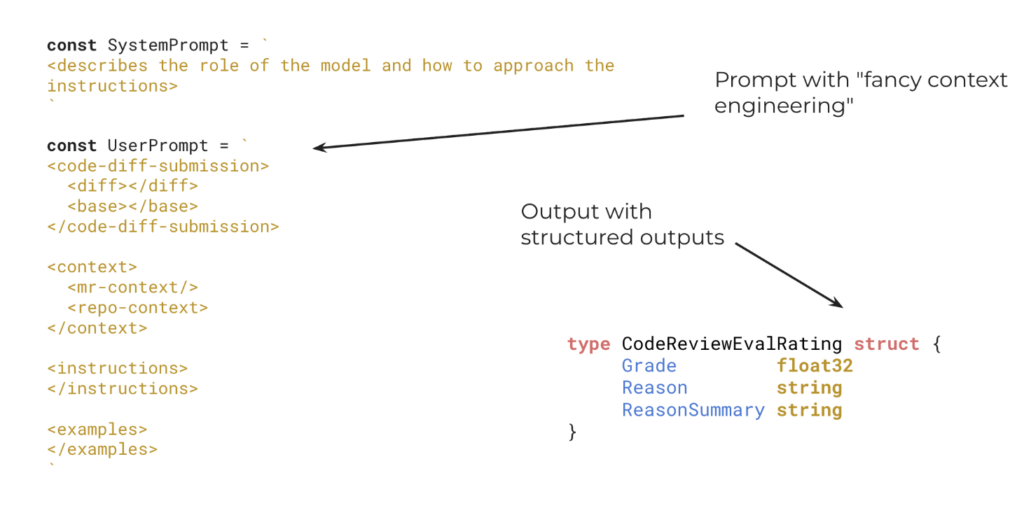
O detalhe de usar saída estruturada dá previsibilidade ao comportamento do sistema, simplifica a integração com o fluxo do GitLab e melhora a auditabilidade, porque o motivo da decisão também fica registrado.
O limite de 30 linhas não é arbitrário
À primeira vista, esse corte pode parecer conservador, mas ele nasce de uma decisão técnica bem fundamentada.
O time precisava operar dentro da faixa em que os modelos continuam realmente eficazes para tarefas de análise. Embora alguns LLMs aceitem janelas de contexto enormes, isso não significa que mantenham a mesma precisão ao longo de todo esse volume.
O problema é conhecido como context rot e significa que o modelo perde capacidade de recuperar com precisão trechos processados anteriormente quando o contexto cresce demais.
No caso do Auto Approval, isso importa muito porque o modelo precisa manter em jogo ao mesmo tempo:
- – as instruções da tarefa,
- – o diff submetido,
- – o código-base relacionado,
- – e o contexto do repositório.
Ao limitar o tamanho das mudanças, o time aumentou a probabilidade de que a análise permanecesse dentro da faixa de maior efetividade do modelo. Em outras palavras: o objetivo não era avaliar o maior número possível de casos, mas avaliar bem os casos certos.
Escolha do modelo e seu impacto na engenharia da solução
Durante a criação do sistema, o time avaliou diferentes opções e chegou ao Gemini 2.5 Flash como melhor ponto de equilíbrio para aquele problema. A decisão considerou custo, throughput, latência e desempenho em benchmarks relacionados a código e uso de janelas de contexto longas, como LiveCodeBench, Aider Polyglot e MRCR v2.
Depois de uma análise técnica, o Gemini 2.5 Flash apareceu como a melhor escolha por combinar:
- – bom custo-benefício em tokens por acurácia,
- – throughput alto,
- – boa performance em tarefas relacionadas a code risk evaluation,
- – e efetividade competitiva em contextos longos.
O ponto aqui não era apostar no modelo “da moda”. O processo, na verdade, foi muito cuidadoso. O time partiu do comportamento que precisava da inferência e só depois escolheu o modelo que melhor atendia àquelas restrições.
Essa lógica continua válida mesmo com novas iterações de modelos: o critério permanece o mesmo, ainda que o modelo específico possa mudar.
GenPlat: a camada que tornou esse uso viável em escala
Outro componente importante da arquitetura foi a GenPlat, a plataforma de IA generativa do iFood, que centraliza acesso a mais de 150 modelos e adiciona recursos como rate limiting, sanitização de privacidade, guardrails de segurança e fallback entre provedores.
Na prática, isso permitiu que o Auto Approval operasse com mais segurança e governança. Ao invés de cada produto falar diretamente com um provedor isolado, a solução se apoia em uma camada comum, preparada para lidar com volume, controle de uso e requisitos de proteção de dados. O diagrama da arquitetura também mostra esse papel da GenPlat entre o worker que processa merge requests e os modelos consumidos na nuvem.
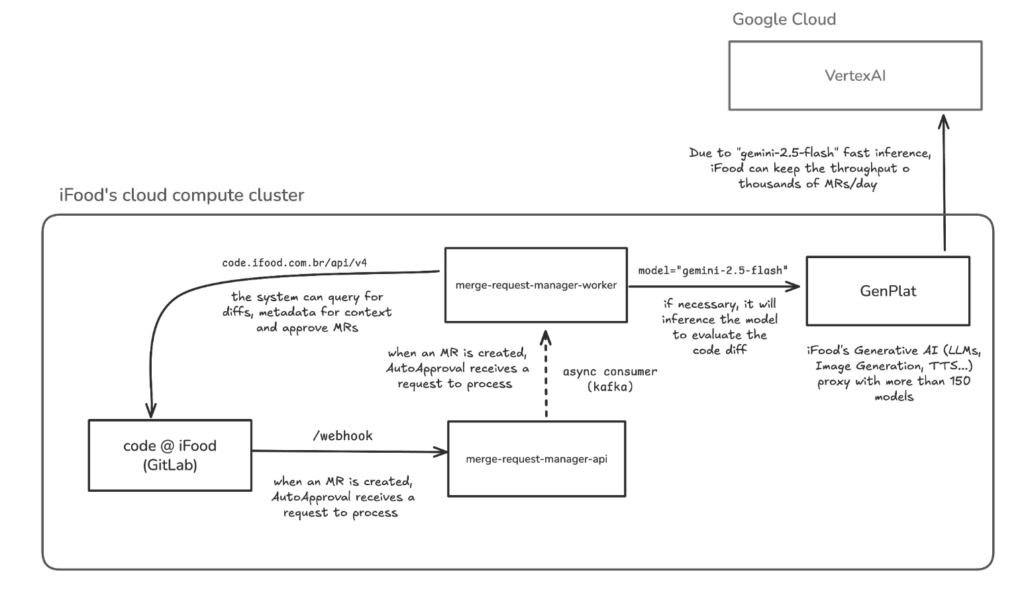
Ter uma base sólida, especialmente no nosso contexto, no qual dezenas de milhares de MRs precisam ser analisadas todos os meses, essa base faz toda a diferença.
Menos espera para destravar trabalhos simples
Os números mostram que o projeto saiu do campo da hipótese.
Em um recorte apresentado pelo time em Agosto de 2025, o Auto Approval lidou com cerca de 21 mil MRs no total, analisou aproximadamente 16 mil e aprovou por volta de 7 mil. No mesmo período, o tempo de aprovação de MRs com menos de 30 linhas caiu de 12 horas para 5 horas, enquanto a curva global de tempo de aprovação no iFood caiu de 65 horas para 43 horas.
Além disso, o custo operacional permaneceu muito baixo. Hoje, a média mensal está abaixo dos US$ 90, com latência média de 13,07 segundos por análise. Se trabalhássemos com outros modelos de benchmarks semelhantes, esse valor poderia superar os US$ 3.000 por mês.
Não é só a IA que faz esse projeto brilhar
O Auto Approval não chama atenção apenas porque usa IA. Ele chama atenção porque usa IA de um jeito disciplinado.
A solução não tentou resolver tudo de uma vez. Não colocou o modelo para arbitrar qualquer tipo de mudança. Não tratou LLM como caixa-preta mágica. Pelo contrário: definiu bem o problema, escolheu um recorte em que a automação era realmente útil, cercou a inferência com contexto e regras, e mediu o impacto com clareza.
No fim, isso diz bastante sobre o tipo de ferramenta que o time de Developer Experience quis construir: algo simples na implementação, mas capaz de remover fricção de uma tarefa complexa e recorrente num ambiente com mais de 2 mil pessoas desenvolvedoras.
E talvez seja justamente aí que o projeto ganhe mais força. Não por tentar substituir tudo, mas por saber exatamente onde acelerar, onde manter o humano no circuito e onde a engenharia precisa ser mais criteriosa do que entusiasmada.
Quando isso acontece, o efeito não é só uma fila menor de merge requests. É uma experiência de desenvolvimento mais fluida, mais confiável e mais alinhada ao ritmo de uma empresa que cresce rápido sem parar de pensar em qualidade.

Paulo Pacitti
Staff Software Engineer
Paulo Pacitti is a Staff Software Engineer at iFood. She is graduated in Computer Science and Engineering, really enjoys videogames and drinking tea.
Build the future at iFood
We are always looking for passionate developers, designers and data scientists to help us revolutionize the food delivery experience. Join iFood Tech and be part of building the future of food technology.
Discover our CareersYou might also like to read
Read more about Back-endAuto Approval: how iFood accelerated code review by 33% with automated risk assessment
From MR queues to automated risk analysis: how context, heuristics, and LLMs revolutionized code review at iFood At iFood, accelerating the engineering process without compromising security and quality is a constant challenge, especially when we consider the scale of our…

Cost Optimization at Scale: The Impact of Kafka Topic Compression at iFood
In iFood's technology ecosystem, real-time data processing is the pillar that sustains everything from real-time driver location tracking to fraud detection in our marketplace. With the exponential growth in data volume, operational efficiency and financial sustainability have become strategic pillars…

Meet other Authors
Each article is the result of the vision and expertise of our authors. See who contributes to our blog:
























