
Repensando a Mensuração: Como nosso MMM Proprietário aprimorou nossa visão de Mídia
Texto escrito por Fernanda Borém, Cientista de Dados Sênior e Mariane Bando, Coordenadora de Ciência de Dados do time de MediaLab.

O marketing digital vive um paradoxo: nunca tivemos tantos dados e, ao mesmo tempo, nunca foi tão difícil isolar efeitos causais. Modelos de atribuição tradicionais capturam conversões diretas, mas deixam pontos cegos: campanhas de branding, canais offline, efeitos de longo prazo, efeitos de awareness.
A questão fundamental permanece: como estimar com confiança o impacto incremental de cada canal e decidir onde alocar o próximo milhão?
Este é o relato de como construímos o Bobyn, nosso MMM (Marketing Mix Model) proprietário, e a plataforma que busca democratizar a modelagem de mix de marketing no iFood.
O Problema: Uma Visão de Marketing no Escuro
Antes do Bobyn, tínhamos um problema clássico de inferência causal: medir o ganho incremental de cada canal de marketing nas KPIs de negócio, realizar simulações de investimentos e otimizar a alocação de budget (seja para sessões, pedidos ou outros KPIs). Os desafios eram previsíveis, mas não triviais:
- Dados limitados: Séries temporais diárias ou semanais são curtas para modelos complexos. Como estimar efeitos individuais de 10+ canais com ~365 observações por ano?
- Canais não-rastreáveis: OOH (out-of-home) e campanhas de branding não geram clicks ou conversões diretas. Como atribuir valor a eles?
- Confounders externos: Feriados, sazonalidade, ações da concorrência, eventos externos (Black Friday, Copa do Mundo). Como isolar o efeito real dos nossos investimentos?
- Efeitos de mídia não são instantâneos: Como modelar persistência temporal de awareness e conversão?
- Saturação de canais: Retornos marginais decrescentes são esperados, mas onde está o ponto de inflexão para cada canal?
Por que não usar algo pronto?
Testamos ferramentas open-source conhecidas (Robyn, Meridian) e consultamos soluções de mercado. O problema não era capacidade técnica delas, inclusive, elas são excelentes, mas nosso contexto (múltiplas verticais, KPIs variados, necessidade de controle fino) pedia uma solução mais customizada:
- Flexibilidade: Precisávamos adaptar rapidamente o modelo para diferentes verticais (food, groceries, pharma) e KPIs (sessões, pedidos, GMV)
- Interpretabilidade: Stakeholders de negócio precisavam entender não só os resultados, mas por que o modelo sugeria determinada alocação
- Controle total: Queríamos iterar rápido, testar priors diferentes, adicionar features customizadas sem depender de roadmap externo
- Conhecimento interno: Já tínhamos uma equipe de DS capaz de construir e manter um modelo Bayesiano customizado
A escolha ficou clara: construir nosso próprio MMM nos daria controle, transparência e a capacidade de evoluir o modelo junto com o negócio.
A Solução: Nosso Próprio Modelo Bayesiano e uma Plataforma Self-Service
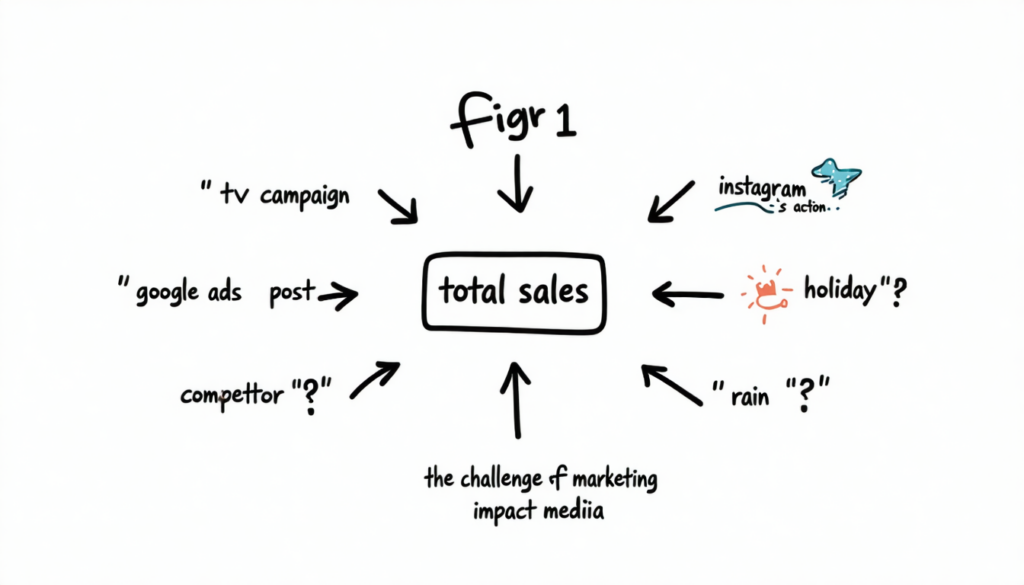
Com um MMM bem calibrado, conseguiríamos responder perguntas que antes dependiam de intuição ou testes A/B difíceis ou até impossíveis de serem realizados, por exemplo:
- Qual o impacto incremental e ROI de cada canal (online e offline)?
- Como realocar budget para maximizar uma métrica específica (sessões, pedidos, GMV)?
- Onde está o ponto de saturação de cada canal?
A solução envolveu duas frentes: construir um modelo que englobasse os desafios da modelagem e torná-lo acessível para toda a empresa.
1. O Cérebro: Nosso Modelo Bayesiano “Bobyn”
Construir nossa própria solução em Python, usando bibliotecas como o PyMC, nos deu controle total. Optamos por modelagem Bayesiana, porque ela nos permitiu ir além dos números frios:
- Conhecimento de Especialista no Código: Conseguimos traduzir o conhecimento de negócio em premissas matemáticas (as “prioris” do modelo). Com muitos canais e uma base mais enxuta de dados, priors Bayesianos ajudam a regularizar o modelo incorporando conhecimento de domínio, facilitando o aprendizado. Assim, oferecemos “dicas” para o modelo, por exemplo: anúncios de TV têm mais efeito prolongado que canais digitais.
- Flexibilidade para o Mundo Real: Modelamos efeitos complexos como a saturação (a curva de retornos decrescentes) e o carryover (o impacto residual de uma campanha ao longo do tempo), tornando as previsões muito mais realistas.
- TV tem efeito mais prolongado que search → prior de decay mais suave
- Digital satura mais rápido que OOH → prior de saturação mais agressivo
- Efeitos não podem ser negativos → distribuição LogNormal
É importante notar que nosso objetivo não é enviesar arbitrariamente — é traduzir conhecimento de marketing em matemática.
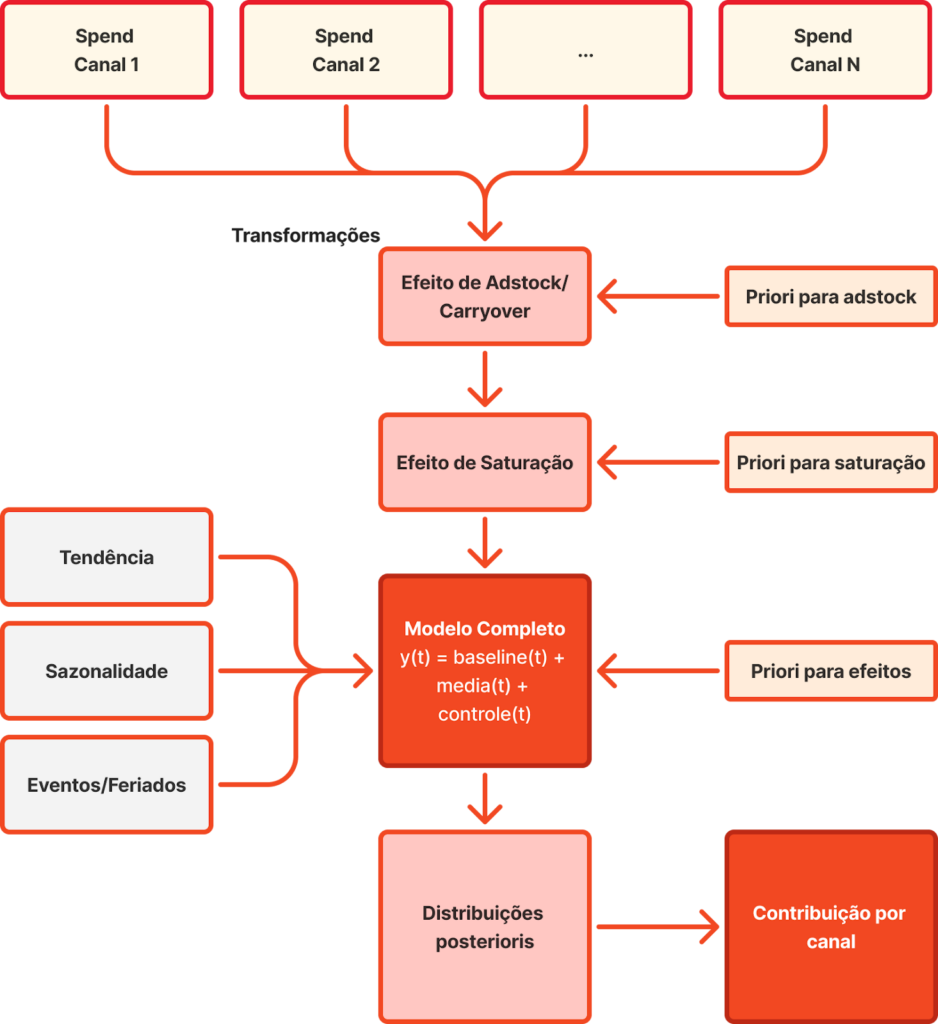
Estrutura simplificada do modelo:
$$ Y_t = baseline_t + Σ (saturação(adstock(spend_canal_i))) + efeitos_t $$
onde:
- baseline_t = tendência + sazonalidade + eventos
- adstock = carryover temporal (geometric decay)
- saturação = Hill transform (retornos decrescentes)
2. O Corpo: A Plataforma de Democratização
Um modelo brilhante nas mãos de poucos tem impacto limitado. Por isso, criamos uma plataforma interna que permite que qualquer analista de negócio crie seu próprio MMM de forma simples e rápida, adicionando conhecimento operacionais de forma simples.
O que a plataforma faz?
- Democratiza o acesso: Qualquer área pode criar, rodar e interpretar modelos sofisticados facilmente, além de configurar prioris de efeito prolongado e saturação.
- Integra o Bobyn: Nosso modelo exclusivo já está integrado, garantindo a qualidade e a consistência das análises.
- Permite simular e otimizar o futuro: Com a ferramenta de otimização e simulação, os times podem responder a perguntas como “o que acontece se…” e tomar decisões mais inteligentes sobre o orçamento.
- Libera nossos Cientistas de Dados: Com a plataforma cuidando da execução, nosso time de DS pode focar no que faz de melhor: evoluir o modelo e atuar como suporte estratégico.
- GenPlat como apoio em insights: Nossa plataforma de LLM traduz e resume os insights, além de responder dúvidas específicas baseadas nos resultados.
Benefício não-planejado
A plataforma simplifica a criação de modelos, mas não elimina a necessidade de conhecimento técnico — e isso é proposital. Sempre que um novo time se interessa, buscamos fazer um onboarding completo: explicamos a metodologia, de onde vêm os números e como interpretar intervalos de credibilidade.
Esse processo virou parte essencial do produto. Percebemos que a confiança nos resultados não vem só da acurácia do modelo, mas de stakeholders entenderem por que o modelo sugere determinada alocação. A plataforma facilita a experimentação, mas o aprendizado técnico continua sendo necessário — e desejado.
O Impacto: Da Incerteza à Decisão Estratégica
O resultado é uma solução robusta que está se expandindo por toda a empresa, muito além do time de marketing. Tornou-se uma ferramenta estratégica de planejamento.
Um dos grandes apoiadores do projeto foi o time de Branding, que tem buscado ser cada vez mais Data-Driven para tomar decisões de investimento Historicamente, a área tem altos investimentos em mídia offline, logo a grande dor sempre foi: estamos investindo demais ou de menos? Mais ainda, estamos investindo corretamente?
Usando o otimizador e o simulador de cenários da nossa plataforma, o time conseguiu ter respostas para essas dúvidas, o que permitiu gerar e testar novas alocações de orçamento entre os canais, sem comprometer um único real do plano.
O resultado? Em Setembro, o time conseguiu reduzir o investimento em 2% – um número bem expressivo no absoluto – em alguns canais saturados mantendo o volume total de sessões.
O Próximo Capítulo da Mensuração
Construir o Bobyn foi desafiador, mas valeu a pena. Ter controle total sobre o modelo significa que podemos iterar rápido, adicionar features customizadas e, principalmente, explicar para stakeholders exatamente de onde vêm as recomendações.
E este é só o começo. Já estamos explorando os próximas desafios:
- Integração com experimentação
Estamos calibrando o MMM com resultados de testes de geolift. A ideia é usar a incrementalidade medida via experimentos para sugerir as distribuições priors, criando um ciclo de validação entre metodologias.
- Atribuição digital como input
Ao longo desses últimos meses, também aprimoramos nossos modelos de atribuição (MTA), assim, o próximo passo é usar as distribuições dos modelos de MTA para informar as priors dos canais digitais no MMM. Essa abordagem é especialmente útil para canais com baixo volume de dados históricos.
Lições aprendidas:
Build vs buy não é binário: Ferramentas como Robyn (Meta) e Meridian (Google) são excelentes e resolvem bem para muitos casos. Mas nosso contexto — múltiplas verticais (food, groceries, pharma), KPIs variados (sessões, pedidos, GMV, ROI), necessidade de iterar rápido — pedia customização profunda.
- A decisão não foi “criar tudo do zero”. Usamos PyMC-Marketing como base e construímos em cima. O ganho real veio da flexibilidade: quando o time de CRM pediu para incluir push notifications como “canal”, ajustamos o modelo em 2 semanas. Com ferramenta terceirizada, isso seria roadmap de trimestre.
- Atenção: bibliotecas abertas exigem conhecimento sólido de teoria Bayesiana e do código base. Não é “plug and play” — você precisa entender o que está acontecendo sob o capô.
Interpretação > acurácia: Stakeholders confiaram no modelo não somente porque ele tinha métricas boas, mas porque entenderam a lógica por trás. A transparência venceu a complexidade.
É importante investir tanto tempo em visualizações e explicações, quanto em tuning de priors. Os gráficos de contribuição, saturação e simulações interativas geraram mais confiança que um diagnóstico de modelo perfeito.
Self-service tem limite: A plataforma acelerou a adoção, mas o onboarding técnico continua essencial. Não queremos criar modelos mal configurados, porque isso gera decisões ruins.
Sobre nós
Prazer, nós somos o time de MediaLab no iFood! Nosso trabalho é construir ferramentas de dados que ajudam os times de mídia, branding e CRM a tomarem decisões melhores: do Bobyn (MMM) a agentes LLM para hiper personalização de notificações.
Se você trabalha com marketing analytics, experimentação ou modelagem Bayesiana e quer trocar ideias, chama a gente no LinkedIn ou comenta aqui embaixo!

Mariane Bando
Data Scientist Lead
Coordenadora de Ciência de Dados no iFood. É mãe da Olívia, ama cozinhar, maratonar séries e ler.
Construa o futuro no iFood
Estamos sempre em busca de desenvolvedores, designers e cientistas de dados apaixonados para nos ajudar a revolucionar a experiência de entrega de alimentos. Junte-se à iFood Tech e faça parte da construção do futuro da tecnologia alimentar.
Conheça nossas CarreirasVocê também pode gostar de ler
Ler mais sobre Dados & IA
Sugar, Revisor e Pepper: o ciclo agêntico que mantém a escala e a consistência do catálogo do iFood
Catálogos vivos exigem sistemas vivos. E, em um catálogo com milhões de itens, a consistência é o fator mais importante. Em um catálogo com milhões de itens, a classificação de produtos enfrenta desafios que vão além da simples categorização. Descrições…







O futuro das notificações push: como a IA generativa do iFood entrega comunicações únicas aos usuários
Como a IA generativa do iFood conecta personalização e comunicação através de padrões rigorosos de engenharia para escalar experiências únicas de usuário De Campanhas Agrupadas para Decisões Individuais [16:30, terça-feira] Não almoçou ainda, né? O Risoto de Funghi que você…



Como o iFood Aprimorou a Gestão de Features para Combater a Fraude
Nesta publicação, apresentamos como o iFood se beneficiou da utilização de uma Plataforma de Features, que além de simplificar o gerenciamento de features, também proporcionou uma infraestrutura robusta, eficiente e mitigou problemas de latência anteriormente enfrentados na detecção e combate à fraudes.

Conheça outros Autores
Cada artigo é resultado da visão e expertise dos nossos autores. Veja quem contribui com nosso blog:

















