
From papyrus to queries: Alexandria at the center of iFood’s business rules
“My number doesn’t match that one.”
A chill down the spine shakes the data analyst. Discomfort, brief silences, promises that “the numbers will be checked again.” This corporate nightmare scenario is a constant fear hanging over data teams in every meeting that involves more than one team discussing the same metrics.
As organizations grow, sharing truths becomes increasingly complex. Word of mouth, hallway conversations, “I am the documentation” become increasingly inefficient to ensure everyone knows the most appropriate way to gather relevant numbers for decision-making, and comprehensive, fast, and far-reaching knowledge-sharing mechanisms become all the more relevant.
In practice, what we see among data teams in general is the multiplicity of tables being generated on the same subjects, often with slightly different business logic; close enough for one to think we’re talking about the same thing, distant enough for friction and discussions to arise about what the correct number would be.
iFood is a reference in Brazil for its aptitude in working with data, which made it possible to build a solid foundation for making constantly data-driven decisions. This mindset has brought us to where we are today, through high-growth cycles over recent years.
In this scenario of rapid progress, the speed required in decision-making resulted in redundancies, lack of governance in rule definition, lost or conflicting data, and underutilized platforms, among other problems. These factors generated unnecessary costs, directly impacting the company’s financial results. Also noteworthy is the absence of responsibility for basic business indicators, leading to multiple results that diverge from each other about the same event, making it difficult to make quick and assertive decisions.
Why Alexandria?
This critical situation has already been faced by several organizations in earlier phases of data management development, with notable examples including major companies like Airbnb, Spotify, and DoorDash [1], [2], [3]. In the past, the absence of standardization, efficiency, consistency, and scalability in data led these companies to significant challenges that, over time, lost confidence in data quality and saw their security in decision-making gradually reduce. With time, they overcame these difficulties by developing specific solutions, such as the Minerva (Airbnb), Metrics Hub (Spotify), and Semantic Layer (DoorDash) platforms, all operating within the specificities of each company, but with a common objective: serving as a central repository of metrics.
It was thinking about the results of these three companies and our own pain points that the Alexandria project was born. Inspired by the ancient Library of Alexandria from the 3rd century BC — an immense place that housed knowledge materialized in hundreds of thousands of parchment scrolls, covering areas of philosophy, science, history, drama, among others — our project came to be the most complete repository of business rules, features, and other functionalities of iFood.
Materially, Alexandria is a Python library combined with some automated routines so that its functionalities can also be used within the SQL environment of Databricks.
In practice, it is an abstraction that seeks to address the problems described above. The major challenge in tracking the solution to this problem is that we are left to monitor counterfactuals: Alexandria is being effective when tables are not created, when business rules are not multiplied, when discussions are not raised in meetings because everyone is aware of the same numbers. Since it’s not possible to track the errors and confusion that didn’t happen and the resources that weren’t wasted, it seems more intelligent to assume that if the Data team effectively sees value in the tool, then we observe both qualitative and quantitative impacts on the team’s routine.
Quantitatively, we measure usage: by May 2025, we counted more than 1700 rules registered in the library and, on average, approximately 166 new rules are registered per month. The following chart illustrates the evolution of the number of rules in the library since its foundation in October 2023.
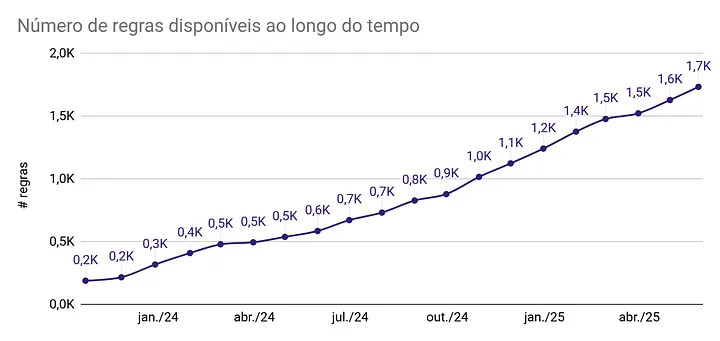
Another important metric is the cross-organizational impact, which can be measured by the library’s usage in production ETLs. In May 2025 alone, almost 240 notebooks using at least one rule in Alexandria were counted. ETLs built using the library are those that seek to ensure cross-functional compliance of the metrics calculated there, therefore, they are ETLs that are preventing themselves against the problems the library seeks to address.
Qualitatively, we have cases and stories that demonstrate both the cross-functional alignment capability and the flexibility and efficiency of our tool.
Integration Case Between Teams: synergy through governance and efficiency of indicators
Throughout Alexandria’s development, we highlight a fundamental milestone: the strategic integration between Alexandria and the Management team, responsible for creating Impact and Sustainability reports — a cross-functional area dedicated to centralizing KPIs from various iFood fronts. Such responsibility demands reliable, traceable, and aligned data, not only for internal use but also to ensure the credibility of reports before external audits and stakeholders.
Historically, data collection for sustainability reports was a fragmented process, depending on dozens of spreadsheets, multiple focal points, and countless manual validations. In a single cycle, for example, more than 28 spreadsheets were used, totaling approximately 565 indicators monitored by 15 distinct teams from various business fronts — a scenario that made standardization, reliability, and agility challenging tasks.
The integration initiative was born from the Management team’s need to ensure not only efficiency but mainly governance and transparency in data access. Alexandria, in this context, began to assume the role of central repository for key indicators, promoting traceability, conceptual alignment, and continuous updating of rules. With the implementation of new functionalities — such as the notification system for rule changes and explicit registration of those responsible for each indicator — we increased security and reduced the risks of misalignment in decision-making processes.
This collaborative process involved a series of actions from both teams: mapping indicators and involved areas, prioritizing critical topics, joint definition of standardization criteria, training participants in the use and registration of rules in Alexandria, continuous communication with stakeholders, and the elaboration of robust documentation ensuring history and project sustainability. Discussions began to occur transparently within the platform’s own channel, promoting accountability and speed in resolving divergences.
As a result, only in the last cycle, the Management team exceeded its goal by registering 118 indicators — of these, 75 translated into Alexandria rules, demonstrating the system’s flexibility and scalability, since a single parameterized rule can meet different reporting needs. Process optimization was evident: while previously the annual data update required up to three months of work, in this cycle the same task was completed in just three weeks.
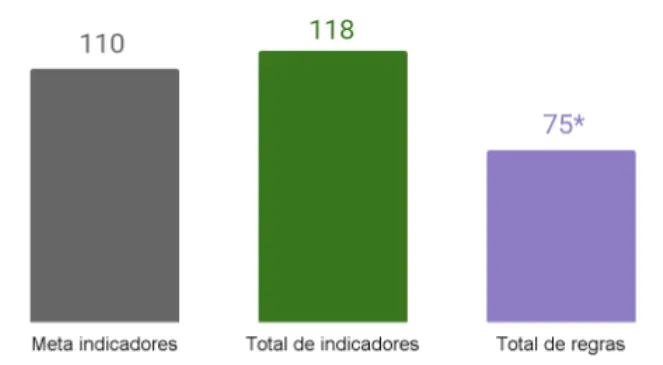
The synergy between Alexandria, Management, and other involved areas not only optimized efforts and mitigated risks but paved the way for an increasingly automated and integrated process. This case reinforces how structured collaboration between teams and continuous evolution of tools and methodologies are essential to elevate iFood’s data governance standards, preparing the company for even greater challenges and future sustainable growth cycles.
Case of flexible data architecture for evolving processes
Another critical challenge faced by the company can be solved by Alexandria: organizing data for analytical consumption in the restaurant onboarding process on the platform. This process, divided into two fundamental stages — Self-Sign In (contract signature through self-service) and Self-Setup (profile creation with all necessary information to receive orders) — represents a crucial flow for our marketplace growth.
Effective analysis and monitoring of this process requires precise capture of relevant events throughout the entire integration journey. However, we faced a significant challenge: our product evolves rapidly, which means that relevant events are constantly created, discontinued, and reordered.
The traditional approach would be to maintain a monolithic ETL responsible for capturing all relevant events, requiring redesign and modification with each process change. However, we opted for a more agile and scalable proposal: building standardized queries for each process event, compartmentalizing the calculation of each event in the Alexandria library and maintaining a production ETL that serves only to unite the results of these queries.
This modular architecture brings a significant advantage: adding or removing events can be accomplished through a simple update to a Python list containing the names of the relevant queries for the specific ETL. Simultaneously, modification to event capture rules can be implemented directly in Alexandria, affecting only the events that need to be modified, ensuring a truly modularized and scalable structure.
Although the analytical layer created is still relatively new, we already observe significant impacts. The flexibility in modifying and creating events allowed the team to iterate and rebuild solutions much faster, quickly adapting to the needs of business and product teams. This approach has also facilitated metric alignment between diverse teams, enabling agile construction of new events requested as stakeholders begin to use the available analytical layer.
How does it work in practice?
Alexandria is a Python library developed to solve the problems of our analytical environment considering four main pillars:
- Governance, by unifying the concept of rules and disseminating the understanding, access, and construction of indicators and business results, eliminating divergences;
- Scalability, by allowing the construction of our data products to meet the demands and constant evolutions of data and business teams and by facilitating the integration, operationalization, and management of rules;
- Efficiency, by centralizing and reducing costs and time in calculating cross-functional indicators;
- Resilience, by ensuring consistent delivery of rules within adequate timeframes, contributing to more agile decisions.
Alexandria offers three types of rule functionalities: filters, columns, and queries, which we will explain in sequence, and also enables the use of adapters, which are metadata files specific to certain data areas, and are not considered rules. Together, rules and adapters allow data and business analysts to perform queries within their analytical environment. All this information is registered in a GitLab repository called Codex, in honor of the type of handwritten book commonly used in antiquity. More recently, it’s also possible to obtain features that are exclusively used by the Data Science and Machine Learning team, but we won’t go into details in this article about how these work.
Regarding the use of rules — filters, columns, and queries — the library is organized following the hierarchical structure of iFood areas separated into domains, subdomains, and modules down to business rules. Access to rules can be done both in Python and SQL. In the first case, using Python’s autocomplete feature, each stage of the hierarchy is obtained by typing “.”, which lists all available options at that level of navigation. In SQL, usage is slightly different: each rule registered or updated in the Codex repository is converted into a function and becomes available in the Databricks catalog. However, there are still limitations in the conversion process, which prevents 100% of existing rules in Codex from being available in SQL.
To make the functioning of filters, columns, and queries clearer, let’s exemplify the practical use of each one. We will demonstrate their use only in Python, for simplicity.
Filters:
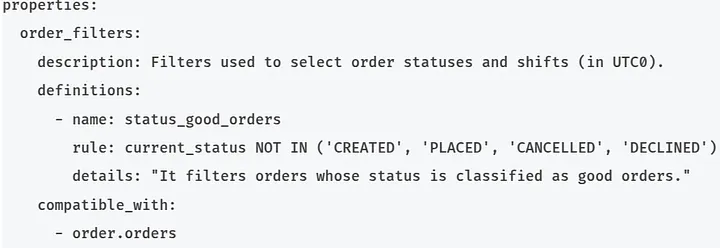
These are rules used in Alexandria to filter a source table. This rule is registered in a .yaml file, where it’s necessary to specify the name, a description, the business rule itself as a SQL expression, and the source table compatible with the rule. Check below the definition of the completed orders filter and how to use it:
Domain: orde
Subdomain: ov4
Product: status
File: filters.yaml
Rule: order_filters.status_good_orders
To use, simply access the data product and create the column using PySpark’s filter function:
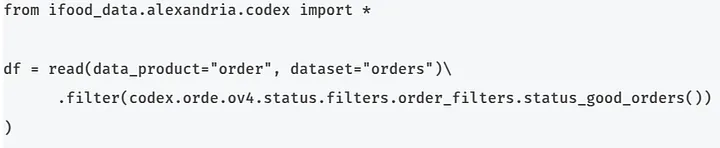
When we say that the rule must be compatible with the source table, we refer to the existence of the current_status column specified in rule in the data product registered in compatible_with.
Columns:
These are rules used in Alexandria to create a column in a source table. Like in the case of filters, this rule is also registered in a .yaml file and requires the same types of information. See in the example below how to create a column that performs date conversions:
Domain: orde
Subdomain: ov4
Product: orders
File: columns.yaml
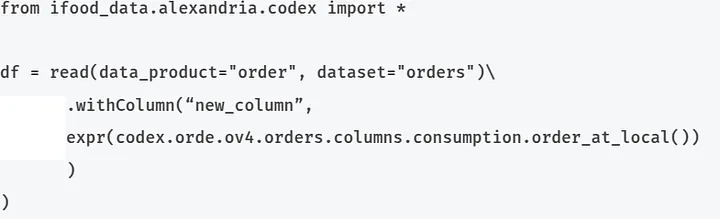
Rule: consumption.order_at_local

To use, simply read the data product and create the column using PySpark’s native withColumn function
Queries:
These are rules used in Alexandria to obtain an already processed table. Unlike filters and columns, queries are registered in files with .sql extension and the file name itself is the rule name. Queries are very versatile, as it’s possible to specify parameters so that users can adjust the table in the way they need to analyze, without worrying about the definition that generated the table. To register this type of rule, it’s necessary to specify metadata such as description, tables used, primary key, and parameters with their respective types, written as a header in yaml format as comments, and subsequently, specify the SQL code. The query in the following example generates an aggregated table with the total completed orders per shift in a given time period.
Domain: orde
Subdomain: ov4
Product: status
File: queries/total_concluded_orders_by_shift.sql
Rule: total_concluded_orders_by_shift


To use a query, it’s not necessary to specify the source table, since data products (the sources) are already used in the code itself. As the rule above has parameters, simply choose the desired values. In this particular case, it’s necessary to define the start and end dates:

It’s worth noting that filters and columns can also be parameterized like queries and their usage is very similar to what was demonstrated in this last example.
With the examples shown so far, we can see that, with few lines of code, data and business analysts can easily abstract from their decision to define the business rule. With this, Alexandria ensures concept standardization, greater agility in the analytical process, and mitigation of errors arising from the multiplicity of definitions due to subjective interpretation by analysts. Thus, the rule registered in Alexandria ensures that data products generated by different teams within iFood have consistency in their concepts and, with this, can bring alignment in their data-driven decisions. Additionally, Alexandria doesn’t materialize any rule, avoiding processing and storage costs.
For our knowledge repository to grow, collaboration from iFood teams is essential, since each area is responsible for defining its own business rules. In this context, Alexandria is considered a community project in constant evolution, fed by the active participation of its members. For the repository to be in continuous development, we defined roles and responsibilities for what we call the three main personas:
- administrators, who ensure rule governance and manage the platform, providing support to all community members;
- codeowners, responsible for defining and sustaining rules over time, keeping them always updated and available for use;
- analysts, who are the consumers of these rules and who need the guarantee that they are correct and operational to make business decisions with precision. Whenever necessary, analysts rely on the help of codeowners to request the registration and/or updating of rules.
Conclusion
With Alexandria, iFood took a decisive step toward excellence in data management and utilization, consolidating the best practices of governance, efficiency, scalability, and resilience. More than a technical tool, the project symbolizes a paradigm shift in how we work with data, transforming information into actionable data that guides strategic decisions and drives our results.
Alexandria’s success will be all the greater as our community engagement increases. Active collaboration from the personas is and will continue to be fundamental to expand and strengthen the rule repository, ensuring it continues evolving alongside iFood’s needs. Thus, we structure a solid foundation for the future, creating a functional, cohesive data environment prepared for the challenges ahead.
Text written in partnership with Celso Mattheus C. Silva, data analyst at iFood.

Celso Silva
Data Analytics
Especialista de Dados no iFood, num longo caminho desde a formação em Relações Internacionais. Entre dados, viagens e projetos voluntários, está sempre buscando aprender algo novo.
Construa o futuro no iFood
Estamos sempre em busca de desenvolvedores, designers e cientistas de dados apaixonados para nos ajudar a revolucionar a experiência de entrega de alimentos. Junte-se à iFood Tech e faça parte da construção do futuro da tecnologia alimentar.
Conheça nossas CarreirasVocê também pode gostar de ler
Ler mais sobre Dados & IA
Sugar, Revisor e Pepper: o ciclo agêntico que mantém a escala e a consistência do catálogo do iFood
Catálogos vivos exigem sistemas vivos. E, em um catálogo com milhões de itens, a consistência é o fator mais importante. Em um catálogo com milhões de itens, a classificação de produtos enfrenta desafios que vão além da simples categorização. Descrições…







O futuro das notificações push: como a IA generativa do iFood entrega comunicações únicas aos usuários
Como a IA generativa do iFood conecta personalização e comunicação através de padrões rigorosos de engenharia para escalar experiências únicas de usuário De Campanhas Agrupadas para Decisões Individuais [16:30, terça-feira] Não almoçou ainda, né? O Risoto de Funghi que você…



Como o iFood Aprimorou a Gestão de Features para Combater a Fraude
Nesta publicação, apresentamos como o iFood se beneficiou da utilização de uma Plataforma de Features, que além de simplificar o gerenciamento de features, também proporcionou uma infraestrutura robusta, eficiente e mitigou problemas de latência anteriormente enfrentados na detecção e combate à fraudes.

Conheça outros Autores
Cada artigo é resultado da visão e expertise dos nossos autores. Veja quem contribui com nosso blog:

















