
How I went from ‘Where’s the README?’ to 2nd place in Hackathon in 9 months
First week as an intern: I cloned the repository, had never seen such a dense application. Kafka, Kubernetes, APIs. Silent panic.
Nine months later: 2nd place in the internal tech hackathon, competing with more than 90 teams (majority of mid-level and senior developers). Our solution? Platform that optimizes subsidy allocation — one of the biggest costs in foodtech, using Machine Learning to suggest optimal allocation, but maintaining human control for strategic adjustments.
How did I get here? It wasn’t genius. It was making mistakes in production on important dates, surviving brutally honest code reviews, asking 10 thousand questions and, mainly, focusing on solving real problems, not learning technologies because they’re hype.
If you’re starting out and thinking you’re “not technical enough,” come with me. This is the story of 1 year without filter with various details of the process: impostor syndrome sensations, first deploy, first incident and a silver medal that still surprises me!
When college meets reality (and gets blue screen)
My final project in Software Engineering class was a review system about accessibility. Simple website. Three files. Local database. Ran on my machine. Grade 10.
First task at iFood: migrate our service from Canary 1.0 to Canary 2.0. My reaction: “Canary? What bird is this?” After reading the documentation: “Ah, it’s just updating some YAMLs in GitLab CI. Seems simple.” It took 24 commits to work. And each commit was a lesson about what college doesn’t teach. Only day-to-day work, with teamwork and lots of dedication!
Quick context about the scenario:
- Canary deploy is gradual rollout — you deploy new code to 5% of traffic, monitor, keep increasing (20%, 40%, 60%, 100%). If it breaks? Quick rollback, only 5% affected. Difference between bringing down app for 500 thousand vs 10 million users.
- Canary 2.0 was an initiative from the Developer Experience team, better known as DevX, to make the process safer and auditable — promotion/suspension via FoodCTL (standardized CLI) instead of free configurations in GitLab CI.
Step by step of the 24 commits (or rather, the summary of pain)
Commits 1-8: Following the guide to the letter (or almost)
I was methodical. Read the documentation, followed step by step. Deactivated old configs, one per commit. Added new configs, one per commit. YAML with millimetric indentation. Opened MR. Ran the pipeline. It broke.
Commits 9-18: “Why doesn’t this thing work?” phase
Documentation said it would work. It didn’t work. I started the guessing phase:
- Maybe it’s the variable name? (changed it, it wasn’t);
- Maybe some configuration is missing? (copied from other repositories, it wasn’t);
- Maybe it’s the order in YAML? (changed it, it wasn’t);
Each attempt: one commit. Each commit: hope. Each pipeline: frustration.
Commits 19-24: Pair programming saves lives!
After commit 18, I was stuck. Completely lost. Asked for help. Senior dev pair programmed with me. In 20 minutes we found it: weights array configured wrong + old variable hidden in the file.
Alone? Would have taken hours. With help? Solved before lunch.
What I learned:
- Production ≠ college: Error isn’t a bad grade — it’s millions of affected users;
- Infrastructure as code is code: YAML deserves review, tests, attention;
- Documentation is a map, not GPS: It doesn’t warn you about all the potholes;
- Pair programming > suffering alone: 20 minutes with help > 3 hours stuck.
Service migrated. Process safer. And the lesson: “simple task” doesn’t exist. The first time? There will be hidden complexity. And 24 commits. And that’s okay.
When “Just Propagate a Header” Becomes Something Much Bigger
Migrating Canary was intensive CI/CD school. But the real test came after: doing my first real feature deploy. The task: propagate header x-ifood-test-flag: loadTest in Kafka events from Delivery Order. And the main thing, the context: when the team does load test (simulates millions of orders to test capacity), these events can’t mix with real data. Otherwise? Polluted metrics, false alerts, useless dashboards.
Solution: propagate header through the entire event chain. If the order came from test, mark as test. Simple, right? Spoiler: no. What seemed simple: “Just add an attributes field to the DeliveryOrder entity, receive the header, propagate to Kafka.”
What it actually was:
- Alter database schema: New column in PostgreSQL, migration, rollback strategy;
- Update contracts: Every service that consumes DeliveryOrder needs to know this field exists;
- Propagation logic: Receive header → save in database → emit to Kafka → ensure backward compatibility;
- Null safety: What if it comes null? What if it comes empty? What if it comes with wrong format?
First commit: working code (I thought).
Code review: “Missing tests. What if attributes is null? Coverage is 60%, raise it to 80%.”
Second round: added tests, null handling. Code review: “This if can be simplified. Extract this logic to a function.”
Third round: refactored. Finally approved. Deploy: time to use the Canary I migrated.
Remember the 24 commits to migrate Canary 2.0? Time to reap the fruits.
Gradual deploy via FoodCTL: 5% → 20% → 40% → 60% → 100% in 1 day (with lots of caution and coffee). Header propagating? Data separated? The difference? Confidence. If something broke, rollback in seconds.
What I learned:
- “Adding a field” is never simple: There’s database, contracts, backward compatibility, tests;
- Code review is free class: Each round taught something — coverage, clean code, edge cases;
- Process > code: Having canary, tests, monitoring gave me confidence to deploy without panic;
- Backward compatibility matters: System has to work before, during and after the change.
Result: header propagated, data separated, clean dashboards. And me? Intern with first feature serving millions of events per day.
Small? Maybe. But it was my code, in production, solving real problems.
From breaking monitors to optimizing millions in subsidies: 9 months make a difference
With xx time at iFood, there was an announcement of an internal hackathon: 3 days, 90 teams, majority mid-level and seniors. My reaction? “Am I ready for this?” I was. But not the way I imagined. The challenge: iFood of the Future.
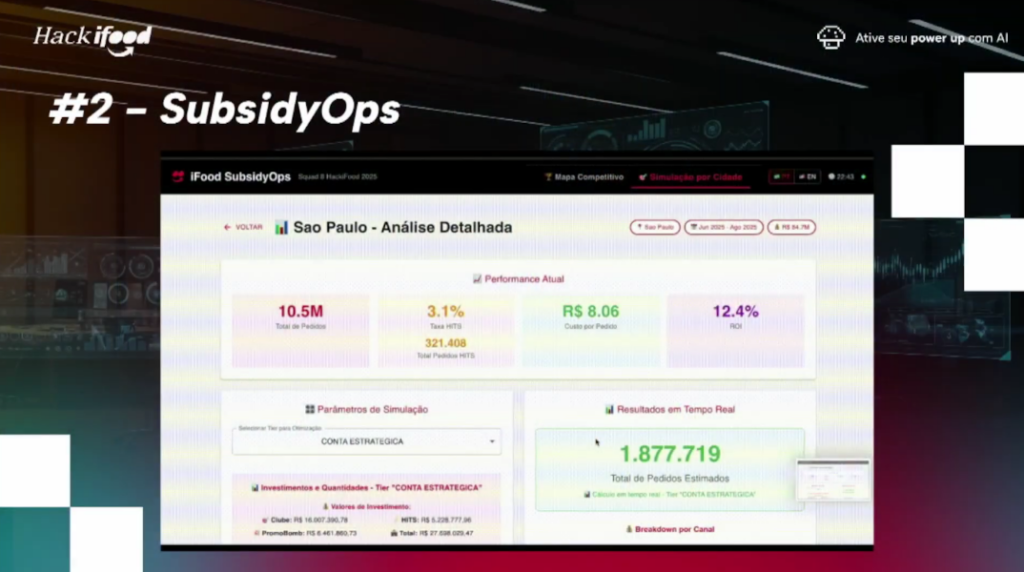
We chose to attack a problem that burns millions per quarter: inefficient subsidy allocation. The context: iFood invests heavily in coupons, cashback, free shipping to win orders. But distribution is complex — different regions, different elasticity, restaurants on multiple apps.
The metric that matters? Cost per incremental order — how much you spend on subsidy to win each new order. Our solution: ML + human control.
We built a platform that balances automation + strategic decision:
- Linear regression model trained with 6 months of historical data. Objective function: minimize cost/order.
- Orchestrator AI with real-time simulation. User adjusts subsidy, system shows instant impact: “If you increase 20% in South Zone, you gain X orders with cost Y”.
- Interactive dashboard with multi-app merchant monitoring and comparison: current allocation vs optimal suggested.
- Stack: Golang (backend), React (frontend), real production data.
The differentiator: majority of teams proposed 100% automated solutions. We went in the opposite direction, for example, machine learning as a decision tool, not substitute. Why? Because allocation involves variables that model doesn’t capture: seasonality, competitive strategy, commercial policies.
Result: 2nd place! We showed the jury (CTOs, VPs) potential reduction in cost/order validated with backtesting. We focused on: solving real problem, with measurable impact, in viable timeframe. And it worked.

Another fact to be proud of:
I was invited to record the next year’s internship program with focus on sharing about innovation in daily work. Several candidates reached out to me through social media to receive guidance and I was able to share my experience.
What changed in 9 months:
It wasn’t technical knowledge — it was mindset. I’ll exemplify with my questions on Slack:
Month 1: “How do I run this locally?”
Month 9: “P99 latency at 800ms on /orders, already checked APM, looks like N+1 query. Does eager loading or cache make sense?”
The difference? I learned to investigate before asking, contextualize problems, bring hypotheses. I still ask many questions. Just now they’re better. Today I make technical decisions alone with team support, for example, algorithms, retry policy, rollback. But when I have doubts? I always ask. Because autonomy isn’t always being right, but knowing when you can decide and when you need validation.
Reflection:
I’m still an intern. I still have a lot to learn.
But today, when I open that huge repository, I don’t feel panic. I feel curiosity. And sometimes — like in the hackathon — I feel I can solve problems that truly matter.
What I would tell the “Me” from 1 year ago
If I could go back in time and talk to the nervous intern from the first day, I would say:
1. You don’t need to know everything
Nobody expects that. What they expect is curiosity, willingness to learn and humility to ask for help. Impostor syndrome is real, but everyone feels it, even seniors.
2. Ask a lot — but learn to investigate first
Experienced devs don’t know everything by heart. They know where to look. Learn to read logs, documentation, code. Then ask with context.
3. Code review is not personal criticism
It’s the best free class you’ll have. Absorb every feedback. Ask the “why” behind each suggestion. And review your own code before asking for review.
4. You WILL make mistakes in production
And it’s okay. What matters is having process to mitigate quickly, learn and not repeat. Poorly resolved merge conflicts happen. Learn and move on.
5. Focus on solving real problems, not learning hype
Machine learning, blockchain, generative AI are cool. But solving business problem with adequate technology > using trendy tech without purpose.
If you’re starting in tech: don’t compare your chapter 1 with someone else’s chapter 20. Compare with your previous chapter. Evolution is what matters.
One year of experience doesn’t make you senior. It makes you a more confident intern, with better questions and autonomy to make basic decisions.
And that’s okay. Because engineering is a journey, not a destination.
Now, if you’ll excuse me, I have a code review waiting. And yes, I still review the diff three times before approving!

Pablo Mendes
Software Engineer Intern
Pablo Mendes é estagiário de Engenharia de Software no iFood, mineiro apaixonado por resolver problemas com código — e nas horas vagas, faço músicas.
Construa o futuro no iFood
Estamos sempre em busca de desenvolvedores, designers e cientistas de dados apaixonados para nos ajudar a revolucionar a experiência de entrega de alimentos. Junte-se à iFood Tech e faça parte da construção do futuro da tecnologia alimentar.
Conheça nossas CarreirasVocê também pode gostar de ler
Ler mais sobre Culture and Careers
Conheça outros Autores
Cada artigo é resultado da visão e expertise dos nossos autores. Veja quem contribui com nosso blog:


























