
Canary 2.0: como o iFood transformou deploy em produção em um processo seguro e automatizado
Confira os detalhes da jornada de como automatizamos a decisão de manter ou abortar cada deploy em produção, com redução de 37% no total de incidentes por deployment
Em sistemas distribuídos e operando em larga escala, há um limite claro para o quanto ambientes de teste conseguem representar a realidade. No iFood, esse limite se torna evidente quando observamos o volume e a complexidade das operações envolvidas.
São centenas de serviços interdependentes, milhões de requisições sendo processadas continuamente e um conjunto de interações que não se repete da mesma forma fora de produção. Esse contexto faz com que ambientes de sandbox, embora necessários, não consigam reproduzir o comportamento do sistema em uso real, afinal, nenhum ambiente de teste simula perfeitamente a produção, como tráfego real, padrões de comportamento imprevisíveis e escalabilidade.
Essa constatação não levou a uma tentativa de eliminar o uso de produção como ambiente de validação, mas sim ao cenário contrário. Percebemos que a aceitação de que é justamente em produção que o sistema se revela de forma mais completa. E, a partir desse ponto, a questão deixa de ser como evitar testar em produção e passa a ser como estruturar esse processo de forma segura, controlada e previsível.
A solução do Canary 2.0 nasceu exatamente dessa necessidade e foi desenvolvido com Kubernetes e Argo Rollouts, organizando o rollout de novas versões de código de forma progressiva, monitorada e reversível, permitindo que o comportamento da aplicação seja validado com dados reais antes de uma promoção completa.
Quando o crescimento expôs os limites do Canary 1.0
A primeira versão do sistema, construída internamente, já permitia controlar o tráfego entre versões, observar comportamento em produção e realizar deploys de forma progressiva. Em um momento inicial, isso representou um avanço importante.
Com o crescimento da arquitetura, surgiram limitações que não eram apenas técnicas, mas também organizacionais. O ferramental havia sido desenvolvido ao longo do tempo por diferentes pessoas, dificultando a evolução contínua e a sua manutenção. Em alguns casos, partes do código já não eram completamente compreendidas pelo time atual, gerando uma série de implicações para a sua evolução.
Do ponto de vista operacional, o fluxo de deploy era fortemente acoplado a pipelines, exigindo edição manual de variáveis e reexecução de jobs para cada etapa do rollout. Além disso, canary e stable rodavam em releases separadas com HPAs independentes, na qual a promoção substituía todos os pods de uma vez, criando risco real de sobrecarga.
Os dados refletem esse cenário: 21% dos deploys não utilizavam o fluxo de canário, e 48% seguiam uma progressão agressiva. O problema não era a ausência de ferramenta, mas a incapacidade dessa ferramenta de induzir o comportamento desejado.
Por que construímos uma camada de proteção em cima do Argo Rollouts
A construção do Canary 2.0 começou com uma mudança clara de perspectiva. A pergunta deixou de ser como melhorar o canário existente e passou a ser como garantir que o deploy aconteça da forma correta, independentemente de quem estivesse operando.
A escolha do Argo Rollouts como base veio após avaliação de diferentes alternativas de mercado. No entanto, o diferencial do Canary 2.0 está na camada construída em cima dessa base, que incorpora regras, restrições e mecanismos de proteção diretamente no fluxo de deploy.
A arquitetura central envolve uma API de deploy que orquestra o ciclo de vida do rollout, traduzindo comandos da CLI em operações do Argo Rollouts via kubectl. Um único arquivo values.yaml configura canary e stable, eliminando a duplicidade do modelo anterior.
A mudança mais importante no modelo de pods: no Canary 2.0, canary e stable rodam na mesma release. Os pods stable estão sempre escalados pelo HPA no número desejado de réplicas, independente do peso do canary. Isso significa que um abort é seguro e instantâneo. Os pods nascem como canary e são promovidos a stable de forma fluida, sem substituição em massa.
Do GitLab para o terminal
No Canary 1.0, operar um deploy significava navegar entre pipelines do GitLab, editar variáveis de CI, reexecutar jobs e interpretar logs fragmentados. O processo era distante do ambiente de desenvolvimento e exigia contexto e experiência que nem todo engenheiro de software no iFood tinha.
O Canary 2.0 trouxe o controle para onde o desenvolvedor já está: o terminal. No iFood, desenvolvemos a Tompero CLI, uma ferramenta de linha de comando que permite visualizar o estado completo de um rollout e operar todo o ciclo de vida do canary com comandos simples: get, promote, abort, retry e restart. Todas as operações também estão disponíveis via API, permitindo integração com automações e workflows existentes.
Com um único comando, o desenvolvedor consegue visualizar de maneira simples:
- – Qual cluster e namespace o serviço está rodando;
- – Qual o status do canary;
- – A barra de progressão com todos os pesos;
- – Se há uma promotion window ou freezing window ativa;
- – Qual o estado de cada pod (canary ou stable).
O screenshot abaixo mostra um get real de um serviço durante um rollout:
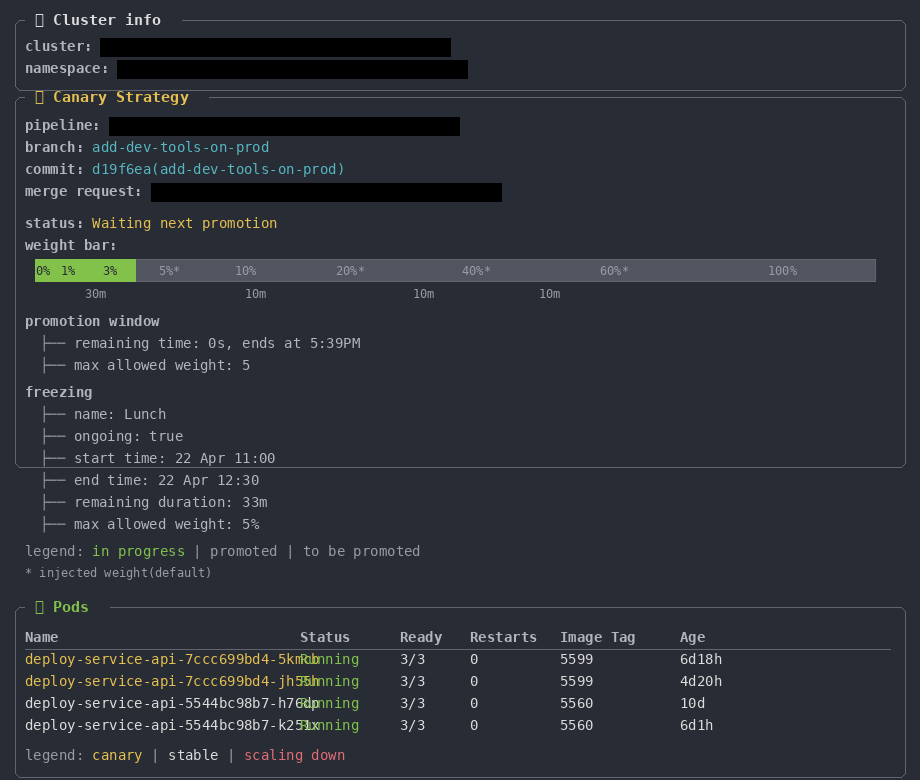
Essa mudança reduz a fricção e aumenta a previsibilidade. A experiência permanece num canal só e o desenvolvedor não precisa sair do terminal, não precisa navegar entre interfaces, e tem visibilidade total do que está acontecendo. Incluindo, inclusive, informações que antes estavam espalhadas entre GitLab, Datadog e Kubernetes.
Progressão estruturada: 0% → 5% → 20% → 40% → 60% → 100%
O rollout segue uma sequência definida em estágios. Cada etapa existe para permitir observação real do comportamento antes de avançar. Para serviços de alto impacto, o modelo inclui promotion windows: janelas obrigatórias de estabilização antes de ultrapassar 5% de tráfego. Serviços críticos podem adicionar mais estágios intermediários; serviços não críticos podem customizar os pesos padrão. O sistema se adapta à criticidade, mas nunca permite pular a progressão.
Detalhes do Freezing Windows
Durante períodos de maior sensibilidade, como horários de pico de pedidos, natural do negócio que opera o iFood, com horários críticos próximos aos horários do almoço e do jantar, o sistema interrompe automaticamente a progressão do rollout. Se um canary está em 20% quando a janela de freezing começa, ele permanece em 20% até o período terminar. Ao final, o processo é retomado a partir do último estado estável, sem intervenção manual.
Essa lógica reconhece algo que muitos sistemas de deploy ignoram: o risco de uma falha às 20h de uma sexta-feira é categoricamente diferente do risco às 10h de uma terça para o iFood.
Canary on Branch: validar antes de mergear
Em fluxos tradicionais, o código precisa ser integrado à branch principal antes de ser validado em produção. Isso cria um dilema: se o merge acontece antes da validação real, código potencialmente problemático já está no trunk. Se a validação acontece antes do merge, quem desenvolve fica bloqueado esperando.
O Canary on Branch inverte essa lógica. É possível iniciar um canary diretamente a partir de uma feature branch, sem necessidade de merge prévio. O sistema direciona uma fração controlada do tráfego para a versão da branch, aplicando os mesmos guardrails de progressão, freezing e promoção de qualquer canary.
Se a validação em produção confirma que o código é saudável, o canary pode ser promovido diretamente para stable, sem precisar passar por um novo deploy a partir da branch principal. Se algo dá errado, o abort é imediato e o código nunca chegou ao trunk.
Na prática, isso reduz o ciclo de feedback de forma significativa. O desenvolvedor recebe a confirmação de que o código funciona em produção antes de integrá-lo. Já para mudanças críticas ou de alto risco, essa capacidade muda a equação de confiança onde o merge deixa de ser um ato de fé e passa a ser uma confirmação de algo já validado.
Auto Abort: automatizando a resposta a falhas
Entre todas as funcionalidades do Canary 2.0, o Auto Abort é a que melhor representa a evolução do sistema. Ele conecta o processo de deploy à infraestrutura de observabilidade, utilizando métricas e testes de regressão para monitorar o comportamento da aplicação em tempo real. Quando um desvio relevante é detectado, o sistema interrompe automaticamente o rollout e retorna para a versão estável.
A arquitetura funciona com dois canais de detecção: o Datadog (via monitors padrão e monitors customizados) e um orquestrador de testes de regressão. Quando um alerta é recebido, o sistema valida se há um canary ativo, verifica se o auto abort está habilitado para aquele serviço, e executa o abort caso necessário. A notificação é enviada automaticamente ao canal do time responsável via Slack.
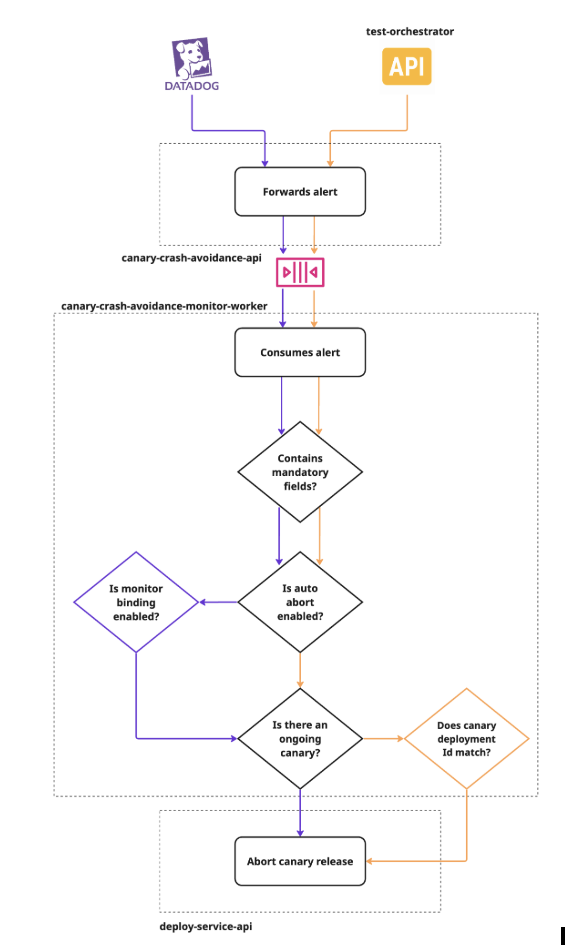
Os times podem habilitar ou desabilitar o auto abort por serviço, vincular monitors customizados do Datadog, e configurar exceções temporárias, tudo via Tompero CLI. Quando um abort acontece, o motivo é registrado e visível ao consultar o status do deployment.
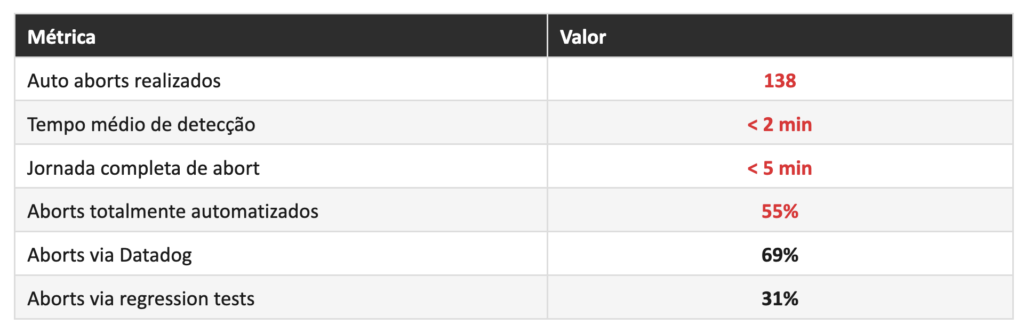
Os números depois da virada
Mudança de comportamento

Impacto em incidentes
- – Redução de 37% no total de incidentes por deployment entre ciclos semestrais;
- – Incidentes mitigáveis caíram 47%.
Adoção em escala

Migração em escala e zero incidentes no processo
A consolidação do Canary 2.0 como padrão não foi apenas consequência da melhoria do sistema, mas também de um esforço coordenado de migração.
Após validação com um grupo inicial de serviços, o time de Developer Experience conduziu a migração centralizada de 881 serviços não-críticos em 3 ondas ao longo de ~3 semanas. As migrações aconteciam entre 4h e 8h da manhã, com war room dedicada para monitoramento. Zero incidentes. Esse modelo de centralizar o que pode ser centralizado, e delegar o que exige ownership, reflete uma maturidade operacional que vai além da tecnologia.
Próximos passos e evolução contínua
Apesar dos avanços, o Canary 2.0 ainda não resolve todos os desafios.
Auto Promote é o próximo passo mais transformador. Hoje, mesmo canaries saudáveis precisam de intervenção manual para avançar entre estágios. O objetivo é que o sistema promova automaticamente quando os sinais de estabilidade são positivos.
Há também esforços para expandir o modelo para aplicações web (ainda desafiadoras em observabilidade e controle de sessão), e a evolução para ambientes multicluster, que aumentam resiliência e reduzem o impacto de falhas localizadas.
Ao estruturar o processo como um sistema com regras claras, mecanismos de proteção e integração com observabilidade, o Canary 2.0 transforma o deploy de um evento pontual em um fluxo contínuo de validação.
Mais do que isso, estabelece um modelo em que produção deixa de ser vista como um risco a ser evitado e passa a ser tratada como a principal fonte de aprendizado sobre o comportamento do sistema.
Os próximos passos seguem exatamente essa direção: mais autonomia, mais cobertura, menos intervenção humana. O objetivo final é que o sistema decida sozinho se cada deploy vive ou morre. Além de que essa decisão seja melhor do que qualquer humano olhando um dashboard conseguiria fazer.

Construa o futuro no iFood
Estamos sempre em busca de desenvolvedores, designers e cientistas de dados apaixonados para nos ajudar a revolucionar a experiência de entrega de alimentos. Junte-se à iFood Tech e faça parte da construção do futuro da tecnologia alimentar.
Conheça nossas CarreirasVocê também pode gostar de ler
Ler mais sobre Back-end
Auto Approval: como o iFood acelerou a revisão de código em 33% com avaliação automática de risco
No iFood, acelerar o processo de engenharia sem abrir mão de segurança e qualidade é um desafio constante, especialmente quando levamos em consideração a escala dos nossos serviços. Com mais de 1.500 pessoas engenheiras, cerca de 10 mil repositórios e…


Otimização de custos em escala: O impacto da compressão de tópicos Kafka no iFood
No ecossistema de tecnologia do iFood, o processamento de dados em tempo real é o pilar que sustenta desde a localização em tempo real de drivers até a detecção de fraudes em nosso marketplace. Com o crescimento exponencial do volume…

Conheça outros Autores
Cada artigo é resultado da visão e expertise dos nossos autores. Veja quem contribui com nosso blog:





























