
Auto Approval: how iFood accelerated code review by 33% with automated risk assessment
From MR queues to automated risk analysis: how context, heuristics, and LLMs revolutionized code review at iFood
At iFood, accelerating the engineering process without compromising security and quality is a constant challenge, especially when we consider the scale of our services.
With more than 1,500 engineers, around 10,000 repositories, and tens of thousands of merge requests (MRs) circulating every month, any stage that becomes a bottleneck quickly stops being an operational detail and starts impacting the overall development experience. Looking at this scenario, the Developer Experience team identified an important bottleneck: waiting time in code review.
From there emerged Auto Approval, a system that uses AI to assess the risk of small code changes and, when they are considered safe, approve them automatically. The result of implementing the new system was a reduction of about 33% in the global merge request approval time and a drop of approximately 58% in approval time for MRs with less than 30 lines.
Beyond just automating one stage, the project sought to accelerate the development flow without increasing the risks involved.
When the problem isn’t reviewing code, but waiting for the review
The Developer Experience team works to ensure that developers have the best possible experience, prioritizing productivity. This involves everything from managing pipelines and automations to taking care of standards, quality tooling, and developing new internal agents.
When measuring different stages of the development cycle, the team noticed that the code review process was consuming more time than it should. In the presented analysis, iFood was dealing with around 18,000 merge requests per month, and the tail of this process was especially heavy: approval time reached 65 hours, while merge time hit 96 hours.
But the most revealing data came right after. Almost half of the analyzed MRs, 48%, had less than 30 lines of changes. In other words: a huge part of the total volume was composed of simple alterations, but they frequently entered the same queue as more complex changes.
In practice, this meant that small adjustments (like specific interface changes, documentation, or localized corrections) could take hours to receive approval, not because they were difficult to review, but because the software engineering team was busy with other priorities.
That’s when the problem started being reformulated.
Reducing the problem
A code review involves many simultaneous dimensions. Style, organization, performance, adherence to internal standards, business context, and security, for example. Letting an LLM decide all of this at once would greatly increase the chance of error, especially in a flow where a false positive (i.e., where the model classified an MR as approved when it shouldn’t have) is too expensive.
So the team chose not to try to automate the code review process itself completely.
Instead, Auto Approval works by evaluating the risk represented by each change. This logic appears explicitly in the technical formulation of the solution, which transforms the broad problem (analogous to the reduction of computational problems in algorithm analysis theory) of approving code changes into a decision about the risk of the submitted diff.
Submitting a prompt like “should this code be approved?” without specifications on how to perform this analysis can encompass various subjective implicit meanings such as: “is this code following the repository’s standardized style?”, “is it correctly structured?” or “is it the most optimized implementation possible?”. This raises the probability of incorrect classifications regarding diff approval. With a prompt like “does this change represent a real risk to the system?”, the evaluation becomes much more objective and aligned with what really matters for the workflows.
The decision was as follows: if the risk is low enough, the MR can be approved automatically and the author can proceed with the merge. If not, the process continues normally to human review.
Removing friction from where it doesn’t need to be
The name might suggest greater autonomy than actually exists, so it’s worth clarifying: the system approves the merge request, but doesn’t merge it automatically. After approval, the author of the change still decides whether to proceed with the merge, ask for additional review, or follow the usual flow. If the change isn’t approved by the system, nothing gets blocked: the MR continues normally to the peer review stage.
This was important to position the tool as an accelerator, not as an absolute substitute for human review.
In practice, the gain appears in very concrete moments. A simple bugfix outside business hours, a small change that needed to get in quickly, or an operational adjustment that didn’t need to sit in the queue for hours. In all these cases, Auto Approval reduces the time between making the request and being able to proceed with the actual merge.
How the system works in practice
Auto Approval listens to GitLab events. When a new merge request is created, it initiates an evaluation sequence that combines eligibility, static analysis, and AI analysis.
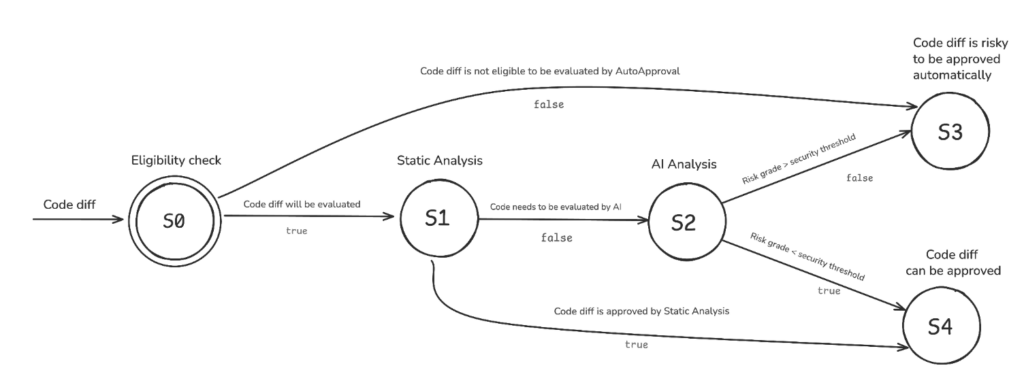
Auto Approval state diagram, showing the flow between eligibility checking, static analysis, AI analysis, and final decision
1. Eligibility checking
Before any diff analysis, the system verifies if that MR can enter the flow.
Some repositories are outside the scope by definition, such as very sensitive systems (financial systems, for example) where risk tolerance needs to be practically zero. Additionally, Auto Approval only operates on small changes: if the diff exceeds 30 lines of altered source code, it doesn’t even proceed to the AI stage.
2. Static and heuristic analysis
If the MR is eligible, the system still goes through a layer of simple rules. Changes to non-sensitive files, documentation, text, or certain types of configuration can be approved at this stage, without needing to send the case to the model.
Static analysis also includes an allow-list of repositories that don’t need code review.
3. AI risk analysis
When the MR needs deeper analysis, the system sends to the model not only the diff, but also a set of additional contexts: base files, merge request title and description, repository structure, README, and file map. The idea is to give the model sufficient context to understand what changed, where it changed, and what role that code plays within the project.
The response is formatted with structured outputs, following a schema defined by the system: a risk score between 0.1 and 1.0, a detailed justification, and a summary. If the score is 0.4 or less, the MR is automatically approved. Above that, there’s no automatic approval and human review will be the next step.
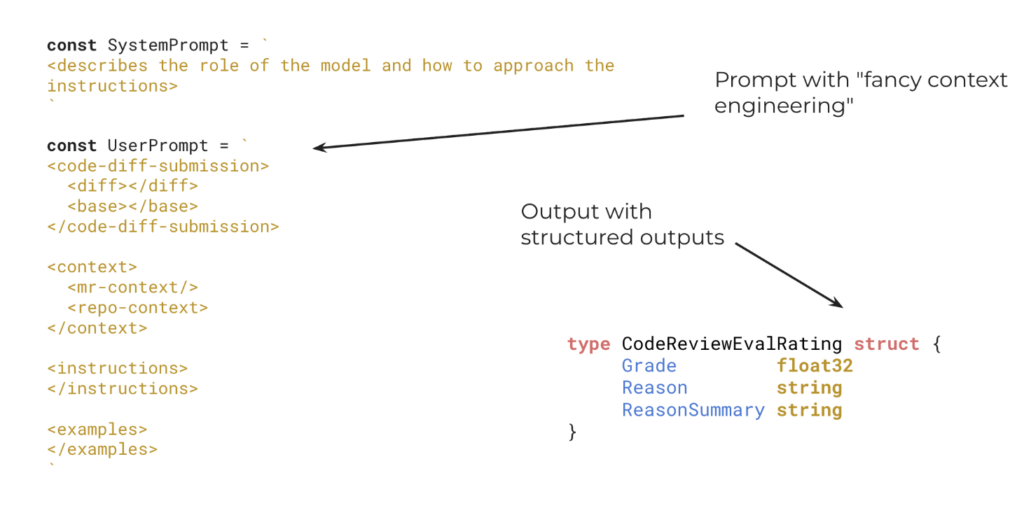
Representation of the input sent to the model (diff and context) and the structured response format with score and justifications
The detail of using structured output gives predictability to the system’s behavior, simplifies integration with the GitLab flow, and improves auditability, because the reason for the decision is also recorded.
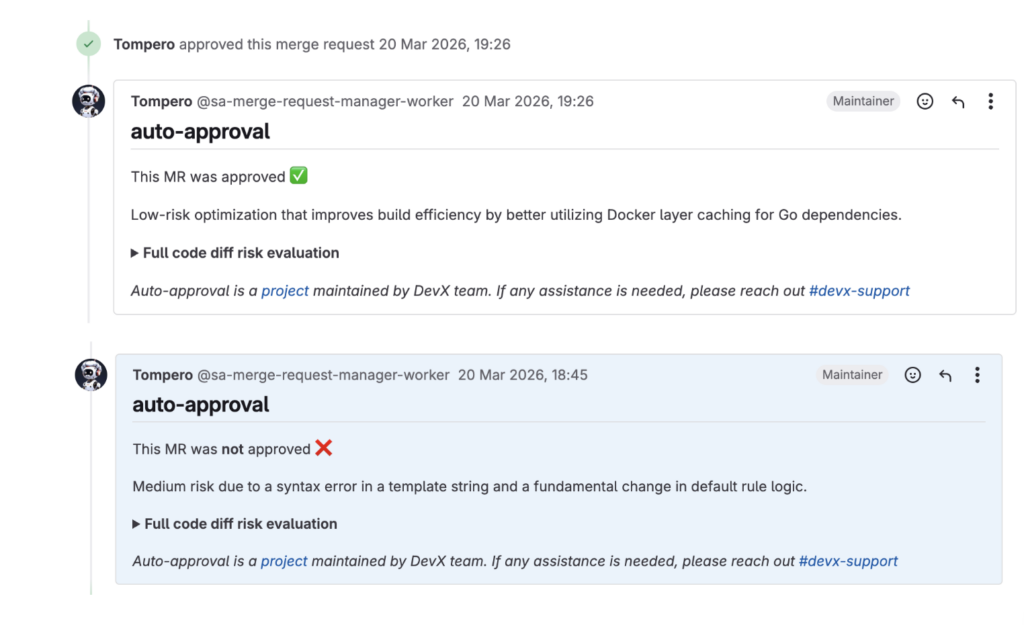
Screenshots of Auto Approval in operation: one shows an automatically approved MR and another, an MR rejected by the system
The 30-line limit is not arbitrary
At first glance, this cutoff might seem conservative, but it stems from a well-founded technical decision.
The team needed to operate within the range where models remain truly effective for analysis tasks. While some LLMs accept huge context windows, this doesn’t mean they maintain the same precision throughout that entire volume.
The problem is known as context rot and means that the model loses the ability to accurately retrieve previously processed segments when the context grows too large.
In the case of Auto Approval, this matters a lot because the model needs to keep in play simultaneously:
- – the task instructions,
- – the submitted diff,
- – the related codebase,
- – and the repository context.
By limiting the size of changes, the team increased the probability that the analysis would remain within the model’s range of greatest effectiveness. In other words: the goal wasn’t to evaluate the largest possible number of cases, but to evaluate the right cases well.
Model choice and its impact on solution engineering
During system creation, the team evaluated different options and arrived at Gemini 2.5 Flash as the best balance point for that problem. The decision considered cost, throughput, latency, and performance on benchmarks related to code and long context window usage, such as LiveCodeBench, Aider Polyglot, and MRCR v2.
After technical analysis, Gemini 2.5 Flash emerged as the best choice by combining:
- – good cost-effectiveness in tokens per accuracy,
- – high throughput,
- – good performance on code risk evaluation tasks,
- – and competitive effectiveness in long contexts.
The point here wasn’t to bet on the “trendy” model. The process was actually very careful. The team started from the behavior they needed from the inference and only then chose the model that best met those constraints.
This logic remains valid even with new model iterations: the criteria remain the same, even though the specific model might change.
GenPlat: the layer that made this use viable at scale
Another important component of the architecture was GenPlat, iFood’s generative AI platform, which centralizes access to over 150 models and adds features like rate limiting, privacy sanitization, security guardrails, and fallback between providers.
In practice, this allowed Auto Approval to operate with more security and governance. Instead of each product talking directly to an isolated provider, the solution relies on a common layer, prepared to handle volume, usage control, and data protection requirements. The architecture diagram also shows this role of GenPlat between the worker that processes merge requests and the models consumed in the cloud.
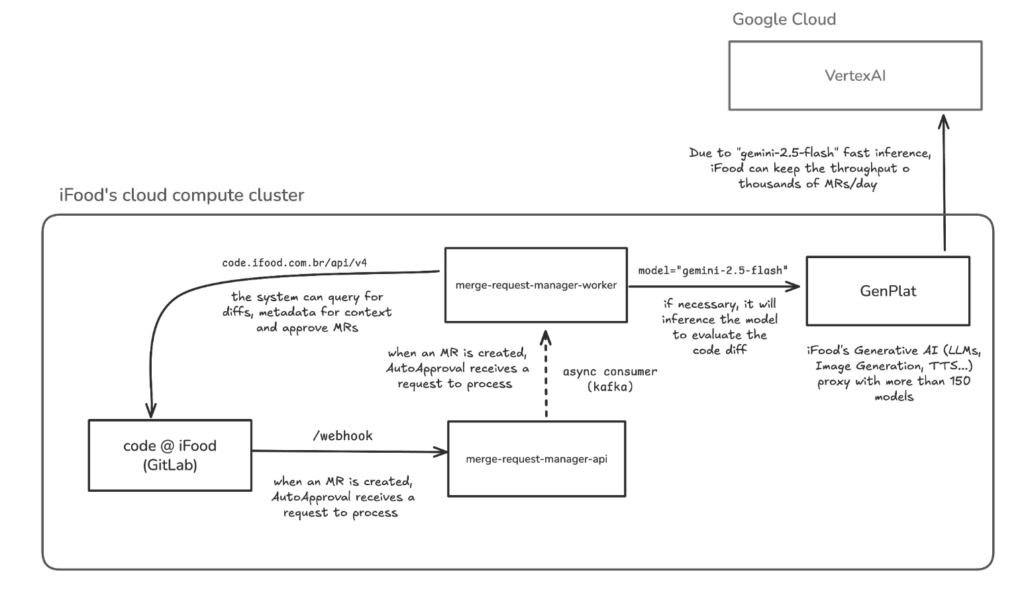
Overview of the Auto-Approval system architecture, represented by the “merge-request-manager” services
Having a solid foundation, especially in our context where tens of thousands of MRs need to be analyzed every month, makes all the difference.
Less waiting to unblock simple work
The numbers show that the project moved beyond the hypothesis stage.
In a snapshot presented by the team in August 2025, Auto Approval handled about 21,000 MRs in total, analyzed approximately 16,000, and approved around 7,000. In the same period, the approval time for MRs with less than 30 lines dropped from 12 hours to 5 hours, while the global approval time curve at iFood dropped from 65 hours to 43 hours.
Additionally, the operational cost remained very low. Today, the monthly average is below $90, with an average latency of 13.07 seconds per analysis. If we worked with other models with similar benchmarks, this value could exceed $3,000 per month.
It’s not just AI that makes this project shine
Auto Approval doesn’t stand out just because it uses AI. It stands out because it uses AI in a disciplined way.
The solution didn’t try to solve everything at once. It didn’t put the model to arbitrate any type of change. It didn’t treat LLM as a magic black box. On the contrary: it defined the problem well, chose a scope where automation was truly useful, surrounded the inference with context and rules, and measured the impact with clarity.
In the end, this says a lot about the type of tool the Developer Experience team wanted to build: something simple in implementation, but capable of removing friction from a complex and recurring task in an environment with more than 2,000 developers.
And perhaps that’s exactly where the project gains the most strength. Not by trying to replace everything, but by knowing exactly where to accelerate, where to keep humans in the loop, and where engineering needs to be more judicious than enthusiastic.
When this happens, the effect isn’t just a smaller merge request queue. It’s a more fluid, more reliable development experience that’s more aligned with the pace of a company that grows fast without stopping to think about quality.

Paulo Pacitti
Staff Software Engineer
Paulo Pacitti é Staff Software Engineer no iFood. É formado em Ciência e Engenharia da Computação, gosta muito de videogames e tomar chá.
Construa o futuro no iFood
Estamos sempre em busca de desenvolvedores, designers e cientistas de dados apaixonados para nos ajudar a revolucionar a experiência de entrega de alimentos. Junte-se à iFood Tech e faça parte da construção do futuro da tecnologia alimentar.
Conheça nossas CarreirasVocê também pode gostar de ler
Ler mais sobre Back-endAuto Approval: como o iFood acelerou a revisão de código em 33% com avaliação automática de risco
No iFood, acelerar o processo de engenharia sem abrir mão de segurança e qualidade é um desafio constante, especialmente quando levamos em consideração a escala dos nossos serviços. Com mais de 1.500 pessoas engenheiras, cerca de 10 mil repositórios e…

Otimização de custos em escala: O impacto da compressão de tópicos Kafka no iFood
No ecossistema de tecnologia do iFood, o processamento de dados em tempo real é o pilar que sustenta desde a localização em tempo real de drivers até a detecção de fraudes em nosso marketplace. Com o crescimento exponencial do volume…

Conheça outros Autores
Cada artigo é resultado da visão e expertise dos nossos autores. Veja quem contribui com nosso blog:

























