
De papiros a queries: Alexandria no centro das regras de negócio do iFood
Introdução
“O meu número não bate com esse”.
Um frio na espinha abala a analista de dados. Desconforto, breves silêncios, promessas de que “os números serão conferidos de novo”. Esse cenário de terror corporativo é um medo constante sobre a cabeça dos times de dados em toda reunião que envolve mais de um time discutindo as mesmas métricas.
À medida que as organizações crescem, o compartilhamento de verdades se torna cada vez mais complexo. O boca-a-boca, a conversa de corredor, a “documentação soy yo” se tornam cada vez mais ineficientes para garantir que todos saibam a forma mais apropriada de se levantar os números relevantes para a tomada de decisão, e mecanismos de compartilhamento de conhecimento abrangentes, rápidos e de longo alcance se tornam tão mais relevantes.
Na prática, o que nós vemos entre as equipes de dados de modo geral é a multiplicidade de tabelas sendo geradas sobre os mesmos assuntos, muitas vezes com lógicas de negócio ligeiramente diferentes; próximas o suficiente para que se pense que estamos falando da mesma coisa, distantes o suficiente para surgirem atritos e discussões sobre qual seria o número correto.
O iFood é referência no Brasil por sua aptidão no trabalho com dados, o que possibilitou construir uma base sólida para tomar decisões constantemente orientadas a dados. Essa mentalidade nos trouxe até aqui, em ciclos de alto crescimento ao longo dos últimos anos.
Neste cenário de rápido progresso, a velocidade exigida na tomada de decisões resultou em redundâncias, falta de governança na definição de regras, dados perdidos ou conflitantes, e plataformas subutilizadas, dentre outros problemas. Esses fatores geraram custos desnecessários, impactando diretamente os resultados financeiros da empresa. Destaca-se também a ausência de responsabilidade por indicadores básicos do negócio, levando à multiplicidade de resultados que divergem entre si sobre o mesmo evento, dificultando em se tomar decisões rápidas e assertivas.
Por que Alexandria?
Essa conjuntura crítica já foi enfrentada por várias organizações em fases anteriores no desenvolvimento em gestão de dados, destacando-se grandes empresas como o Airbnb, o Spotify e a Doordash [1], [2], [3]. No passado, a ausência de padronização, eficiência, consistência e escalabilidade nos dados levou essas empresas a desafios significativos que, ao longo do tempo, perderam a confiança na qualidade dos dados e viram sua segurança na tomada de decisões reduzir gradativamente. Como o tempo, superaram essas dificuldades ao desenvolver soluções específicas, como as plataformas Minerva (Airbnb), Metrics Hub (Spotify) e Semantic Layer (Doordash), todas atuando nas especificidades de cada empresa, mas com um objetivo comum: servir como repositório central de métricas.
Foi pensando nos resultados dessas três empresas e nas nossas próprias dores que nasceu o projeto Alexandria. Inspirados na antiga biblioteca de Alexandria do século III a.C. — um imenso local que abrigava o conhecimento materializado em centenas de milhares de rolos de pergaminho, abrangendo áreas da filosofia, ciência, história, drama, dentre outras -, o nosso projeto veio para ser o mais completo repositório de regras de negócios, features e outras funcionalidades do iFood.
Materialmente, o Alexandria é uma biblioteca em python combinado com algumas rotinas automatizadas para que suas funcionalidades possam ser utilizadas também dentro do ambiente SQL do Databricks.
Na prática, ela é uma abstração que busca enfrentar os problemas descritos acima. O grande problema de se acompanhar a solução desse problema é que resta-nos acompanhar contrafactuais: o Alexandria está sendo eficaz quando tabelas não são criadas, quando regras de negócio não são multiplicadas, quando discussões não são levantadas em reunião porque todos estão cientes dos mesmos números. Como não é possível acompanhar os erros e confusões que não aconteceram e os recursos que não foram desperdiçados, parece-nos mais inteligente assumir que, se o time de Dados efetivamente vê valor na ferramenta, então observamos impactos tanto qualitativos quanto quantitativos na rotina do time.
Quantitativamente, medimos o uso: até maio de 2025, contabilizamos mais de 1700 regras registradas na biblioteca e, em média, são cerca de 166 regras novas cadastradas por mês. O gráfico a seguir ilustra a evolução do número de regras na biblioteca desde a sua fundação, em outubro de 2023.
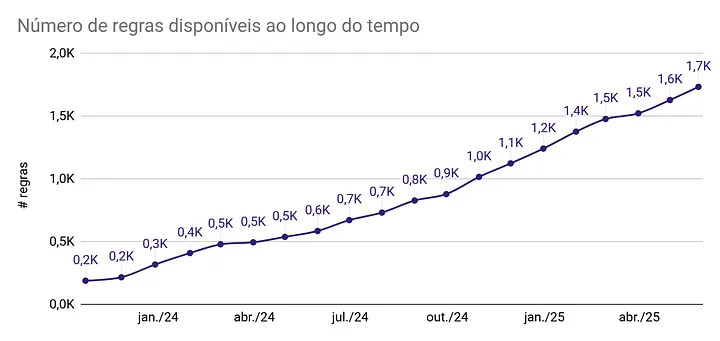
Outra métrica importante é o impacto transversal na organização, que pode ser medido pelo uso da biblioteca nos ETLs em produção. Só em maio de 2025 foram contabilizados quase 240 notebooks usando pelo menos uma regra no Alexandria. ETLs construídos utilizando a biblioteca são aqueles que buscam garantir conformidade transversal das métricas lá calculadas, por isso, são ETLs que estão prevenindo-se contra os problemas que a biblioteca busca sanar.
Qualitativamente, temos casos e histórias que demonstram tanto a capacidade de alinhamento transversal quanto a flexibilidade e eficiência da nossa ferramenta.
Case de Integração entre times: sinergia pela governança e eficiência dos indicadores
Ao longo do desenvolvimento do Alexandria, destacamos um marco fundamental: a integração estratégica entre o Alexandria e o time de Gestão, responsável pela criação dos relatórios de Impacto e Sustentabilidade — área transversal dedicada à centralização dos KPIs de diversas frentes do iFood. Tamanha responsabilidade demanda dados confiáveis, rastreáveis e alinhados, não apenas para o uso interno, mas também para garantir a credibilidade dos relatórios frente a auditorias externas e stakeholders.
Historicamente, a coleta de dados para relatórios de sustentabilidade era um processo fragmentado, dependendo de dezenas de planilhas, múltiplos pontos focais e inúmeras validações manuais. Em um único ciclo, por exemplo, foram utilizados mais de 28 planilhas, totalizando aproximadamente 565 indicadores monitorados por 15 times distintos de várias frentes de negócio — um cenário que tornava a padronização, a confiabilidade e a agilidade tarefas desafiadoras.
A iniciativa de integração nasceu da necessidade do time de Gestão de garantir não só a eficiência, mas principalmente a governança e a transparência no acesso aos dados. O Alexandria, nesse contexto, passou a assumir o papel de repositório central dos indicadores-chave, promovendo rastreabilidade, alinhamento conceitual e atualização contínua das regras. Com a implementação de novas funcionalidades — como o sistema de notificações para alterações de regras e o registro explícito dos responsáveis de cada indicador — aumentamos a segurança e reduzimos os riscos de desalinhamento nos processos de decisão.
Esse processo colaborativo envolveu uma série de ações de ambos os times: mapeamento dos indicadores e áreas envolvidas, priorização dos temas críticos, definição conjunta de critérios para padronização, treinamento dos participantes no uso e cadastro de regras no Alexandria, comunicação contínua com stakeholders, e a elaboração de documentação robusta garantindo histórico e sustentabilidade do projeto. As discussões passaram a ocorrer de maneira transparente dentro do próprio canal da plataforma, promovendo responsabilização e celeridade na resolução de divergências.
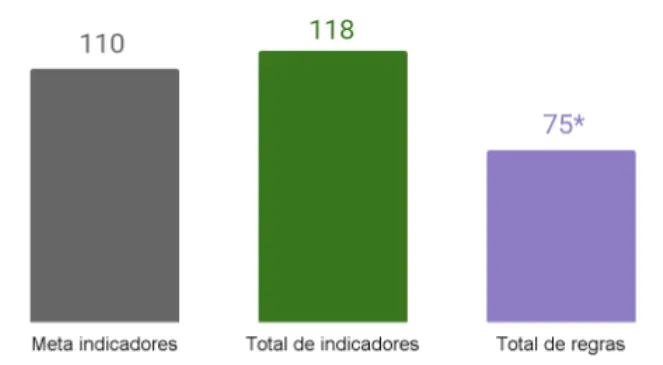
Como resultado, apenas no último ciclo, o time de Gestão superou sua meta ao cadastrar 118 indicadores — destes, 75 traduzidos em regras do Alexandria, demonstrando a flexibilidade e escalabilidade do sistema, visto que uma única regra parametrizada pode atender diferentes necessidades de reporte. A otimização do processo foi evidente: enquanto anteriormente a atualização anual dos dados demandava até três meses de trabalho, neste ciclo a mesma tarefa foi concluída em apenas três semanas.
A sinergia entre Alexandria, Gestão e outras áreas envolvidas não apenas otimizou esforços e mitigou riscos, mas pavimentou o caminho para um processo cada vez mais automatizado e integrado. Este case reforça como a colaboração estruturada entre equipes e a evolução contínua de ferramentas e metodologias são essenciais para elevar o padrão de governança de dados do iFood, preparando a empresa para desafios ainda maiores e futuros ciclos de crescimento sustentável.
Case de arquitetura flexível de dados para processos em evolução
Um outro desafio crítico enfrentado pela empresa pode ser resolvido pelo Alexandria: a organização de dados para consumo analítico no processo de onboarding de restaurantes na plataforma. Este processo, dividido em duas etapas fundamentais — Self-Sign In (assinatura do contrato por autoatendimento) e Self-Setup (criação do perfil com todas as informações necessárias para recebimento de pedidos) — representa um fluxo crucial para o crescimento do nosso marketplace.
A análise e monitoramento eficaz deste processo exige a captura precisa de eventos relevantes ao longo de toda a jornada de integração. No entanto, enfrentávamos um desafio significativo: nosso produto evolui rapidamente, o que significa que os eventos relevantes são constantemente criados, descontinuados e reordenados.
A abordagem tradicional seria manter um ETL monolítico responsável por capturar todos os eventos relevantes, exigindo redesenho e modificação a cada alteração no processo. Porém, optamos por uma proposta mais ágil e escalável: construir queries padronizadas para cada evento do processo, compartimentalizando o cálculo de cada evento na biblioteca Alexandria e mantendo um ETL em produção que serve apenas para unir o resultado dessas queries.
Esta arquitetura modular traz uma vantagem significativa: a adição ou remoção de eventos pode ser realizada através de uma simples atualização em uma lista Python contendo os nomes das queries relevantes para o ETL específico. Simultaneamente, a modificação nas regras de captura dos eventos pode ser implementada diretamente na Alexandria, afetando apenas os eventos que precisam ser modificados, garantindo uma estrutura verdadeiramente modularizada e escalável.
Embora a camada analítica criada ainda seja relativamente nova, já observamos impactos significativos. A flexibilidade na alteração e criação de eventos permitiu ao time iterar e reconstruir soluções com muito mais velocidade, adaptando-se rapidamente às necessidades dos times de negócio e de produto. Esta abordagem também tem facilitado o alinhamento de métricas entre equipes diversas, possibilitando a construção ágil de novos eventos requisitados à medida que os stakeholders começam a utilizar a camada analítica disponibilizada.
Como funciona na prática?
O Alexandria é uma biblioteca em Python desenvolvida para solucionar os problemas do nosso ambiente analítico considerando quatro principais pilares:
- Governança, ao unificar o conceito das regras e ao disseminar o entendimento, acesso e construção de indicadores e resultados de negócio, eliminando divergências;
- Escalabilidade, ao permitir que a construção dos nossos produtos de dados possam atender às demandas e às constantes evoluções dos times de dados e de negócio e ao facilitar a integração, operacionalização e gerenciamento das regras;
- Eficiência, ao centralizar e reduzir custos e tempo no cálculo de indicadores transversais;
- Resiliência, ao garantir a entrega consistente e em prazo adequado das regras, contribuindo para decisões mais ágeis.
O Alexandria oferece três tipos de funcionalidades de regras: filtros, colunas e queries, que iremos explicar na sequência, e também habilita o uso de adaptadores, que são arquivos de metadados específicos para determinadas áreas de data, e não são consideradas regras. Juntos, regras e adaptadores permitem que analistas de dados e de negócio possam realizar consultas dentro do seu ambiente analítico. Todas essas informações estão cadastradas em um repositório do Gitlab chamado Codex, em homenagem ao tipo de livro manuscrito comumente utilizado na antiguidade. Mais recentemente, é possível também obter features que são exclusivamente utilizadas pelo time de Data Science e Machine Learning, mas não entraremos em detalhes neste artigo sobre o funcionamento destes.
No que se refere ao uso das regras — filtros, colunas e queries — a biblioteca está organizada obedecendo à estrutura hierárquica de áreas do iFood separada em domínios, subdomínios e módulos até chegar às regras de negócio. O acesso às regras pode ser feito tanto em Python quanto em SQL. No primeiro caso, usando o recurso de autocomplete do Python, cada etapa da hierarquia é obtida a partir da digitação do ” . “, que lista todas as opções disponíveis naquele nível da navegação. Em SQL o uso é um pouco diferente: cada regra cadastrada ou atualizada no repositório do Codex é convertida em uma função e fica disponível no catálogo da Databricks. No entanto, ainda existem limitações no processo de conversão, o que impede que 100% das regras existentes no Codex estejam disponíveis em SQL.
Para deixar mais claro o funcionamento de filtros, colunas e queries, vamos exemplificar na prática o uso de cada um deles. Iremos demonstrar o seu uso somente em Python, por simplicidade.
Filtros:
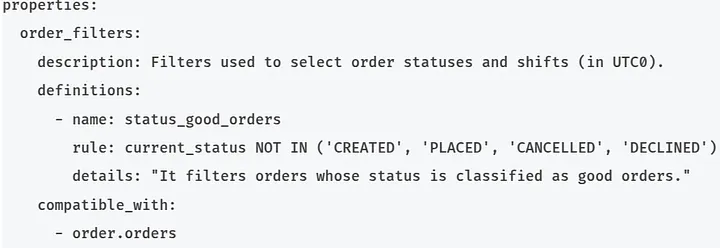
São regras utilizadas no Alexandria para filtrar uma tabela fonte. Essa regra é cadastrada num arquivo .yaml, onde são necessários especificar o nome, uma descrição, a regra de negócio em si como uma expressão em SQL, e a tabela fonte compatível com a regra. Confira abaixo a definição do filtro de pedidos concluídos e como utilizá-lo:
Domínio: orde
Subdomínio: ov4
Produto: status
Arquivo: filters.yaml
Regra: order_filters.status_good_orders
Para usar, basta acessar o produto de dados e criar a coluna utilizando a função filter do PySpark:
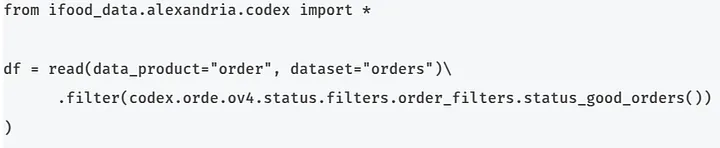
Quando dizemos que a regra deve ser compatível com a tabela fonte, nos referimos à existência da coluna current_status especificada em rule no data product registrado em compatible_with.
Colunas:
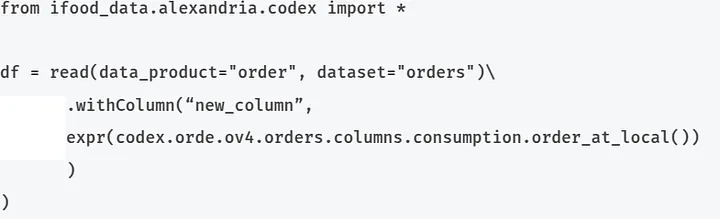
São regras utilizadas no Alexandria para criar uma coluna em uma tabela fonte. Assim como no caso dos filtros, essa regra também é cadastrada em um arquivo .yaml e necessita dos mesmos tipos de informações. Veja no exemplo abaixo como criar uma coluna que faz conversões de data:
Domínio: orde
Subdomínio: ov4
Produto: orders
Arquivo: columns.yaml
Regra: consumption.order_at_local

Para usar, basta ler o data product e criar a coluna usando a função withColumn nativa do PySpark
Queries:
São regras utilizadas no Alexandria para obter uma tabela já tratada. Ao contrário de filtros e colunas, as queries são cadastradas em arquivos com extensão .sql e o próprio nome do arquivo é o nome da regra. Queries são muito versáteis, pois é possível especificar parâmetros de modo que o usuário pode ajustar a tabela no modo que precisa analisar, sem precisar se preocupar com a definição que gerou a tabela. Para cadastrar esse tipo de regra, é necessário especificar metadados como descrição, tabelas usadas, chave primária e parâmetros com seus respectivos tipos, escritos como um cabeçalho em formato de um yaml comentado e na sequência, especificar o código em SQL. A query do exemplo a seguir gera uma tabela agregada com o total de pedidos concluídos por turno em um determinado período de tempo.
Domínio: orde
Subdomínio: ov4
Produto: status
Arquivo: queries/total_concluded_orders_by_shift.sql
Regra: total_concluded_orders_by_shift


Para usar uma query não é necessário especificar a tabela fonte, uma vez que os data products (as sources) já são utilizados no próprio código. Como a regra acima tem parâmetros, basta escolher os valores desejados. Neste caso em particular, é preciso definir as datas de início e fim:

Vale ressaltar que filtros e colunas também podem ser parametrizados como as queries e seu uso é muito similar ao demonstrado neste último exemplo.
Com os exemplos mostrados até aqui, podemos ver que, com poucas linhas de código, o analista de dados e de negócio podem, facilmente, abstrair da sua decisão em definir a regra de negócio. Com isso, o Alexandria garante a padronização do conceito, maior agilidade no processo analítico e a mitigação de erros advindos da multiplicidade de definições por parte da interpretação subjetiva dos analistas. Assim, a regra cadastrada no Alexandria garante que produtos de dados gerados por diferentes times dentro do iFood possuam consistência em seus conceitos e, com isso, possam trazer alinhamento em suas decisões orientadas a dados. Além disso, o Alexandria não materializa nenhuma regra, evitando custos de processamento e armazenamento.
Para que o nosso repositório de conhecimento cresça é essencial a colaboração dos times do iFood, uma vez que cada área é responsável por definir suas próprias regras de negócio. Neste contexto, o Alexandria é considerado um projeto comunitário em constante evolução, alimentado pela participação ativa de seus membros. Para que o repositório esteja em contínuo desenvolvimento, definimos papeis e responsabilidades para o que chamamos de três principais personas:
- os administradores, que garantem a governança das regras e gerenciam a plataforma, prestando suporte a todos os membros da comunidade;
- os codeowners, responsáveis pela definição e sustentação das regras ao longo do tempo, mantendo sempre atualizadas e disponíveis para uso;
- os analistas, que são os consumidores destas regras e que precisam da garantia de que elas estejam corretas e operantes para tomar decisões de negócio com precisão. Sempre que necessário, os analistas contam com a ajuda dos codeowners para solicitar o cadastro e/ou atualização de regras.
Conclusão
Com o Alexandria, o iFood deu um passo decisivo rumo à excelência na gestão e utilização de dados, consolidando as melhores práticas de governança, eficiência, escalabilidade e resiliência. Mais do que uma ferramenta técnica, o projeto simboliza uma mudança de paradigma na forma como trabalhamos com dados, transformando informações em dados acionáveis que orientam decisões estratégicas e impulsionam nossos resultados.
O sucesso do Alexandria será tanto maior quanto for o engajamento da nossa comunidade. A colaboração ativa das personas é e ainda será fundamental para ampliar e fortalecer o repositório de regras, assegurando que ele continue evoluindo juntamente com as necessidades do iFood. Assim, estruturamos uma base sólida para o futuro, criando um ambiente de dados funcional, coeso e preparado para os desafios que estão por vir.
Texto escrito em parceria com Celso Mattheus C. Silva, analista de dados no iFood.

Celso Silva
Data Analytics
Especialista de Dados no iFood, num longo caminho desde a formação em Relações Internacionais. Entre dados, viagens e projetos voluntários, está sempre buscando aprender algo novo.
Construa o futuro no iFood
Estamos sempre em busca de desenvolvedores, designers e cientistas de dados apaixonados para nos ajudar a revolucionar a experiência de entrega de alimentos. Junte-se à iFood Tech e faça parte da construção do futuro da tecnologia alimentar.
Conheça nossas CarreirasVocê também pode gostar de ler
Ler mais sobre Dados & IA
Sugar, Revisor e Pepper: o ciclo agêntico que mantém a escala e a consistência do catálogo do iFood
Catálogos vivos exigem sistemas vivos. E, em um catálogo com milhões de itens, a consistência é o fator mais importante. Em um catálogo com milhões de itens, a classificação de produtos enfrenta desafios que vão além da simples categorização. Descrições…







O futuro das notificações push: como a IA generativa do iFood entrega comunicações únicas aos usuários
Como a IA generativa do iFood conecta personalização e comunicação através de padrões rigorosos de engenharia para escalar experiências únicas de usuário De Campanhas Agrupadas para Decisões Individuais [16:30, terça-feira] Não almoçou ainda, né? O Risoto de Funghi que você…



Como o iFood Aprimorou a Gestão de Features para Combater a Fraude
Nesta publicação, apresentamos como o iFood se beneficiou da utilização de uma Plataforma de Features, que além de simplificar o gerenciamento de features, também proporcionou uma infraestrutura robusta, eficiente e mitigou problemas de latência anteriormente enfrentados na detecção e combate à fraudes.

Conheça outros Autores
Cada artigo é resultado da visão e expertise dos nossos autores. Veja quem contribui com nosso blog:

















