
Como o iFood conseguiu identificar tabelas duplicadas no Data Lake?

O iFood se destaca como uma organização data-driven, onde os desenvolvimentos de produtos e as tomadas de decisões estratégicas são fundamentadas em dados. Para sustentar esse padrão de excelência, é essencial proporcionar aos engenheiros, analistas e cientistas a autonomia necessária para criar e gerenciar suas próprias soluções, promovendo assim uma cultura de inovação e autogestão analítica.
Com esta liberdade, surgem desafios interessantes como o de lidar com a produção e gestão de dados redundantes. Sem um monitoramento eficaz das tabelas do Data Lake (DL), este problema pode resultar em custos desnecessários de processamento e armazenamento, além de aumentar a complexidade do parque de dados.
Na tentativa de identificar e mitigar estas ineficiências, buscamos na literatura algumas possibilidades e acabamos adotando e adaptando o algoritmo proposto por Raunak Shah et al. no artigo “R2D2: Reducing Redundancy and Duplication in Data Lakes“. O trabalho traz uma abordagem inovadora e principalmente barata, do ponto de vista computacional, a qual constrói e refina grafos relacionais entre datasets para identificar tabelas com dados potencialmente redundantes, destacando oportunidades de ganho e simplificação do ambiente de dados corporativo.
Qual foi o ponto de partida?
O algoritmo original é composto pelo encadeamento de três etapas capazes de entregar, como produto final, um mapa de relações entre pares de tabelas cujos dados são potencialmente duplicados. A cada etapa aplicada, seu resultado serve de insumo para a próxima, a qual refina e entrega um conjunto de pares de tabelas mais assertivo que aquele obtido pela etapa anterior. Resumidamente, as etapas são:
➢ Etapa “Schema Graph Builder (SGB)” — Este componente basicamente compara schemas entre tabelas colunares e determina quais são aqueles coincidentes ou que possuem alguma relação de contenção. Por exemplo, se uma tabela A possui todas as colunas da tabela B, isto pode indicar que A contém potencialmente todos os dados de B, tornando B uma fonte de informações duplicadas (portanto, sem necessidade de existência). E estas relações são representadas em forma de grafo.
O SGB utiliza uma abordagem inteligente de clustering para evitar comparações custosas O(N²) entre todas as tabelas. O algoritmo funciona da seguinte forma:
1. Ordenação: As tabelas são ordenadas por cardinalidade de schema (número de colunas) em ordem decrescente;
2. Formação de clusters: Percorre-se a lista ordenada e, para cada schema:
- Se não está contido em nenhum cluster existente → torna-se um novo centro de cluster;
- Se está contido em algum cluster → é adicionado como membro deste cluster;
3. Construção do grafo: Dentro de cada cluster, são criadas arestas direcionadas entre pares de tabelas onde existe contenção real, sempre apontando da tabela maior para a menor.
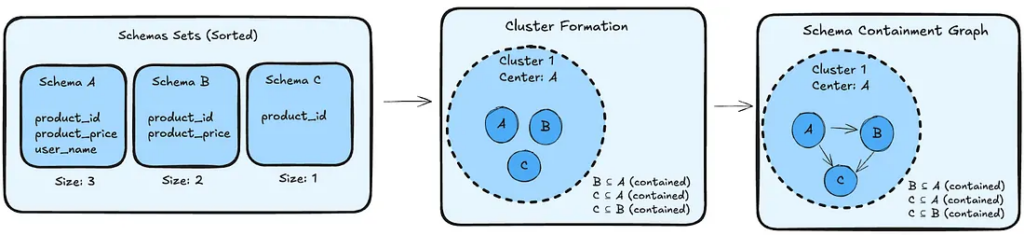
Esta estratégia garante que nenhuma relação de contenção seja perdida, enquanto mantém a complexidade computacional em O(N log N) + O(K(N-K)), onde K é o número de clusters formados — muito mais eficiente que a abordagem de comparar todas as tabelas entre si.
➢ Etapa “Min-Max Pruning (MMP)” — Após a criação do grafo, remove-se algumas conexões (filtragem) com base nos valores mínimos e máximos entre colunas comuns do tipo numéricas. O princípio aplicado é que, se um conjunto de dados A está contido em B, para todas as colunas comuns numéricas, então:
1. O valor mínimo na coluna de A deve ser maior ou igual ao valor mínimo na coluna de B.
2. O valor máximo na coluna de A deve ser menor ou igual ao valor máximo na coluna de B.
Se alguma destas condições for violada, o algoritmo MMP remove a conexão entre os conjuntos de dados no grafo, indicando que a contenção não é possível.
➢ Etapa “Content Level Pruning (CLP)” — Nesta fase, o algoritmo ajusta as relações nos grafos (nova filtragem) examinando os dados das tabelas em si, em nível granular de linha.
O CLP utiliza técnicas de amostragem para decidir se as conexões (ou relacionamentos de contenção potenciais entre datasets) devem ser mantidas ou excluídas. Se o conjunto A está totalmente contido em B, esta relação de contenção deve ser válida mesmo para subconjuntos amostrados de A. Ao consultar subconjuntos específicos de A, e verificar sua presença em B, o algoritmo assegura uma inferência precisa de contenção sem precisar varrer tabelas inteiras.
Limitações
Esta abordagem SGB ⇒ MMP ⇒ CLP demonstrou resultados satisfatórios nos estudos de caso realizados no artigo. Contudo, considerando o contexto específico do iFood e a realidade de uma empresa que lida diariamente com Data & IA em larga escala, identificamos algumas adaptações necessárias para melhor atender ao cenário operacional e às características do nosso DL. Importante: sem deixar de lado a premissa original de compor uma solução eficiente e de baixo custo.
Os principais desafios que motivaram estas adaptações incluem:
- Limitações de infraestrutura para metadados estatísticos: A implementação da etapa MMP, quando trabalhando com tabelas em formato puramente Parquet, é trivial e barata pois os arquivos possuem nativamente valores mínimos e máximos dos dados. Não é o caso de tabelas Delta com as quais trabalhamos no iFood. Isto exigiria uma arquitetura de metadados estatísticos robusta, incluindo: (1) pipelines automatizados para apuração de min/max em todas as colunas numéricas; (2) armazenamento e versionamento destes metadados; e (3) tratamento de edge cases como valores nulos e tipos de dados variados. Esta infraestrutura, embora tecnicamente viável, representaria um investimento significativo e violaria a premissa da solução.
- Overhead de processamento: A comparação entre conteúdos das tabelas, conforme proposta pela etapa CLP, sem o cálculo prévio de valores min/max demandaria recursos computacionais excessivos, impactando a performance e também ferindo a premissa.
- Duplicação inerente à Arquitetura Medalhão: Por natureza, a arquitetura em medalhão pode resultar em duplicação de tabelas. Este cenário é esperado quando dados são ingeridos na camada bronze, processados na silver e posteriormente disponibilizados na camada gold para consumo. Na ausência de transformações significativas entre as camadas, a duplicação de dados torna-se uma realidade.
Como fizemos?
Reformulamos o algoritmo original e substituímos as etapas MMP e CLP por duas novas etapas com o mesmo objetivo de filtragem e refinamento incremental do resultado, mas trazendo a realidade das tecnologias do iFood para o jogo e dando nossa assinatura à solução.
Buscamos preservar e/ou aumentar a precisão e relevância dos resultados e eliminando ao máximo falsos positivos. A imagem abaixo ilustra o algoritmo construído, numa abordagem que batizamos de SGB ⇒ DLP ⇒ LTP.
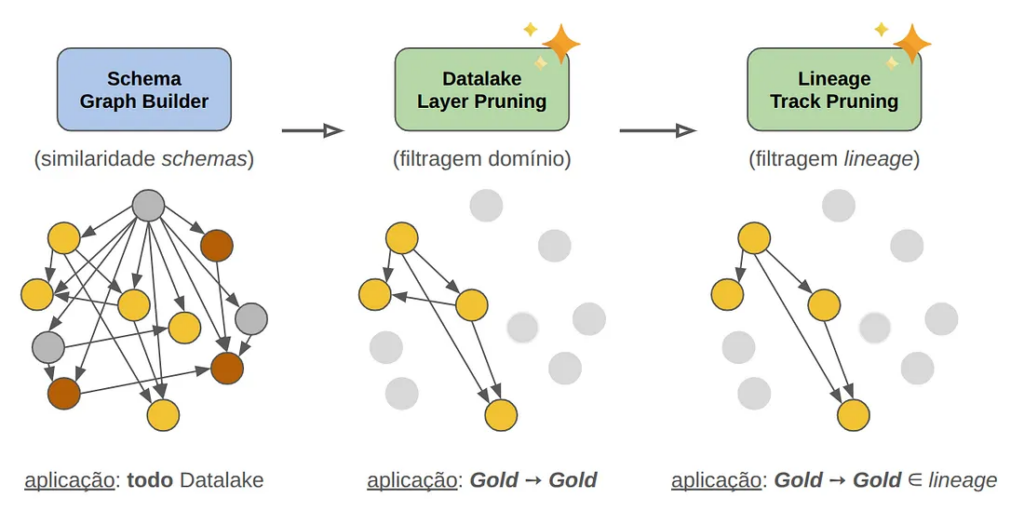
➢ Etapa “Schema Graph Builder (SGB)”
Mantivemos este componente inalterado pois ele oferece a garantia fundamental de 100% de detecção de relações de contenção entre schemas. O SGB continua sendo nossa base sólida para identificar todas as possíveis relações hierárquicas entre tabelas com base nas suas concepções colunares.
➢ Etapa “Data Lake Layer Pruning (DLP)” ✨ NEW ✨
Introduzimos uma filtragem por contexto que permite direcionar o algoritmo para áreas específicas do Data Lake, reservando a potencialidade e assertividade da identificação de informações redundantes a nichos conhecidos e descartando naturalmente redundâncias inerentes a processos internos:
- Filtragem por Domínio: Restringimos a aplicação e análise a domínios de negócio específicos (ex: áreas de Groceries, de Fintech, etc).
- Filtragem por Camada: Focamos em camadas específicas da arquitetura medalhão (ex: bronze, silver, gold).
Benefícios Principais:
- Redução expressiva do escopo e volumetria de dados sob análise, eliminando comparações irrelevantes entre tabelas de contextos completamente não correlacionados.
- Acionamento direto de times de dados e de negócio para validação da solução proposta e também para o endereçamento mais eficaz quando da eliminação/remoção dos dados duplicados identificados.
➢ Etapa “Lineage Track Pruning (LTP)” ✨ NEW ✨
Aproveitamos de um poderoso recurso presente no nosso DL conhecido como Data Lineage e implementamos uma validação por linhagem para eliminar falsos positivos resultantes de coincidências entre schemas:
Como funciona:
- Reconstruímos a linhagem completa de cada tabela (upstreams e downstreams diretos e indiretos), determinando assim toda história dos dados e de suas dependências.
- Mantivemos apenas relações de contenção entre tabelas que possuem conexão real no pipeline de dados (i.e., pertencem a uma mesma storyline).
Impacto Observado:
- Eliminação de falsos positivos: Descobrimos que muitas tabelas tinham schemas similares por pura coincidência, sem qualquer relação real entre seus dados, por vezes resultante de padronizações sistêmicas (por exemplo: tabelas com dados de monitoramento de APIs sempre adotam as mesmas colunas, apesar de se referirem a distintos sistemas).
- Maior precisão: Focamos apenas em relações de contenção que fazem sentido do ponto de vista do fluxo de dados.
Testes e Validações sob Domínio Controlado
Com o protótipo do algoritmo em mãos, chegou o momento de colocá-lo à prova. No lugar de partir direto para uma implementação em ampla escala, adotamos uma abordagem mais estratégica e direcional: selecionamos um Domínio de Negócio específico para servir como nosso laboratório de validação. E o time de Fintech topou a parceria!
Nosso objetivo foi para além de simplesmente medir a taxa de assertividade do algoritmo. Queríamos compreender como os especialistas do domínio perceberam nossa solução e quais insights eles poderiam oferecer para aprimorá-la.
O Resultado que Surpreendeu
Os números falaram por si: de 76 pares de tabelas identificadas como tendo uma potencial relação de duplicidade, 60 delas realmente refletiam informações totalmente redundantes entre si!!! Isto representa aproximadamente 79% de assertividade do algoritmo. Para um primeiro teste, este resultado superou algumas expectativas daquelas mais otimistas.
Destes 60 pares, um total de 30 tabelas puderam ser identificadas como duplicatas e, após sua auditoria detalhada, os especialistas do domínio já puderam tomar ações concretas de limpeza. Os demais pares identificados também envolviam tabelas cujos schemas, linhagens e contextos estavam correlacionados, porém constituíam sub amostragens dos dados umas das outras, por vezes construídas por questões de otimização de processos de leitura de grandes datasets. Apesar de não serem datasets puramente duplicados, abriu-se oportunidade para revisitar e questionar sua real necessidade.
Curiosidade Técnica: desde a construção do grafo primário de relações de duplicidade (etapa SGB) até a filtragem com base no pertencimento à linhagem (etapa LTP), o algoritmo varre todo o Data Lake. Isto envolve mais de 15 mil tabelas com volumetria de algumas centenas de Terabytes!!! Apesar disso, pela natureza hábil da sua construção, este processo leva em torno de 10 minutos numa infraestrutura tímida (alguns poucos workers Spark em instâncias small sized).
O Impulso para a Próxima Fase
Este primeiro resultado teve um efeito transformador na percepção do projeto. A confiança gerada pelos números abriu caminho para duas expansões importantes para torná-lo uma solução robusta e escalável para a companhia:
- Escalabilidade Horizontal: estender a aplicação para todos os domínios do iFood.
- Automação Estrutural: automatizar todo o pipeline, desde a detecção das informações redundantes até a visibilidade e o acionamento dos responsáveis.
A Automação e A Robustez
Nossa solução de automação foi estruturada em três fases principais, cada uma com responsabilidades bem definidas:
Fase #1: Detecção e Análise
O coração do sistema reside no algoritmo principal que executa sequencialmente as três etapas essenciais:
- Schema Graph Builder (SGB): constrói o grafo de contenção identificando relações hierárquicas.
- Data Lake Layer Pruning (DLP): filtra por contexto (domínio & camada) para reduzir ruído.
- Lineage Track Pruning (LTP): utiliza a linhagem para aumentar a assertividade e eliminar falsos positivos com base no pertencimento ao mesmo storyline.
Este processo é orquestrado via Airflow, que garante execução periódica, resiliente e confiável do pipeline. O resultado de cada execução é persistido no Data Lake, criando um histórico rastreável de todas as detecções de potenciais duplicidades.
Fase #2: Comunicação Inteligente
Um segundo componente, também orquestrado via Airflow, consome os resultados da análise de redundância e traduz os insights técnicos em sugestões de ações efetivas.
Utilizando um bot personalizado junto ao principal comunicador adotado pela empresa, o sistema notifica diretamente os proprietários e responsáveis pelas tabelas identificadas como potencialmente redundantes, orientando-os com metadados e facilitando como identificá-las, acessá-las e avaliá-las.
Fase #3: Autonomia na Tomada de Decisão
Em vez de simplesmente informar sobre o problema, oferecemos aos responsáveis notificados opções claras de ação num canal direto para acionamento via comunicador (como, por exemplo, a remoção imediata das tabelas, a inclusão das mesmas em listas de exceção — quando a duplicação é intencional ou necessária, a sugestão de alinhamento entre times para otimização/convergência/redução de datasets essenciais, etc).
Oportunidades de Melhoria
Apesar dos resultados positivos, permanecemos continuamente com o foco em tornar a solução ainda mais eficiente e inteligente. Já identificamos áreas específicas para aprimoramento futuro do algoritmo, dentre elas:
Flexibilidade de Schema
O algoritmo atualmente exige correspondência exata de nomenclatura entre colunas, o que pode deixar de fora alguns casos de relações de duplicidade como consequência de erros de digitação, descontinuidade de padrão no ciclo de vida do dado pós-transformação, etc . Em pipelines produtivos, é comum encontrar tabelas da mesma linhagem com colunas idênticas que foram renomeadas para adequação a processos específicos (ex: customer_id vs. client_id). Essas tabelas, apesar de semanticamente equivalentes, não são detectadas pela atual etapa SGB.
Ambiguidade em Relações Simétricas
Quando duas tabelas possuem exatamente as mesmas colunas, o algoritmo cria uma relação bidirecional (A ⊆ B e B ⊆ A, simultaneamente). Essa situação, embora tecnicamente correta, pode gerar confusão na interpretação dos resultados, exigindo uma análise mais detalhada de qual tabela deve ser removida ou mantida. Este aspecto nos desperta a intenção de adotar soluções em DataViz que cumpram melhor este papel e ilustrem relações em grafos de forma mais inteligível.
Validação Semântica por LLM
Após algumas PoCs (Proof of Concept), identificamos o potencial da inclusão de uma nova camada adicional de validação semântica após o filtro por linhagem. Esta etapa incorpora à solução, para além dos schemas, outras fontes extras de metadados e principalmente os códigos-fonte das ETLs por trás das tabelas envolvidas. Sob esta ótica, temos:
- Análise dos notebooks e códigos que compõem as ETLs usando o poder de análise textual oferecido pelos Large Language Models (LLMs).
- Validação se as transformações no pipeline realmente indicam similaridade de propósito.
- Detecção de casos onde tabelas possuem schemas similares e/ou equivalentes, mas finalidades distintas.
Tais melhorias elevam o algoritmo ao patamar de uma solução que combina análise estrutural com compreensão semântica, aumentando significativamente sua precisão a um custo que conserva sua premissa de entregar um caminho inovador e barato para conservação de um Data Lake saudável.
Conclusão
Nossa adaptação do algoritmo R2D2 demonstrou que é possível gerar valor real adaptando pesquisa acadêmica ao contexto corporativo. Com 79% de assertividade numa primeira aplicação piloto detectando potenciais tabelas redundantes, evoluímos de um experimento controlado e deveras manual para uma solução automatizada completa, com aplicação em todo contexto de Dados do iFood. Esta solução entrega hoje a potencialidade de mantermos nosso Data Lake mais saudável, mais eficiente e reduzido de informações redundantes desnecessárias.
Substituímos componentes complexos e de maior custo, existentes na solução original, por equivalentes mais leves e mais inteligentes, baseados em filtragem direcionada ao contexto do negócio e incorporando recurso poderoso de Data Lineage. Esta abordagem reduziu com segurança falsos positivos e se alinharam à nossa realidade tecnológica com mínimo esforço.
As oportunidades de melhoria identificadas — flexibilidade de schemas, tratamento de relações simétricas e validação semântica por LLM — apontam para uma próxima iteração ainda mais precisa e inteligente.
Referências
R2D2: Reducing Redundancy and Duplication in Data Lakes [2023]; Raunak Shah et al.; Proceedings of the ACM on Management of Data, Volume 1, Issue 4 (DOI: https://doi.org/10.1145/3626762 — alternative: arXiv:2312.13427)
Texto escrito em parceria com
Rafael Mattos, engenheiro de dados & IA no iFood.

Daniel Ozeas
Data Engineer
Engenheiro de Dados no iFood. Apaixonado por tecnologia, curte fazer trilhas e estar próximo à natureza.
Construa o futuro no iFood
Estamos sempre em busca de desenvolvedores, designers e cientistas de dados apaixonados para nos ajudar a revolucionar a experiência de entrega de alimentos. Junte-se à iFood Tech e faça parte da construção do futuro da tecnologia alimentar.
Conheça nossas CarreirasVocê também pode gostar de ler
Ler mais sobre Dados & IA
Sugar, Revisor e Pepper: o ciclo agêntico que mantém a escala e a consistência do catálogo do iFood
Catálogos vivos exigem sistemas vivos. E, em um catálogo com milhões de itens, a consistência é o fator mais importante. Em um catálogo com milhões de itens, a classificação de produtos enfrenta desafios que vão além da simples categorização. Descrições…







O futuro das notificações push: como a IA generativa do iFood entrega comunicações únicas aos usuários
Como a IA generativa do iFood conecta personalização e comunicação através de padrões rigorosos de engenharia para escalar experiências únicas de usuário De Campanhas Agrupadas para Decisões Individuais [16:30, terça-feira] Não almoçou ainda, né? O Risoto de Funghi que você…



Como o iFood Aprimorou a Gestão de Features para Combater a Fraude
Nesta publicação, apresentamos como o iFood se beneficiou da utilização de uma Plataforma de Features, que além de simplificar o gerenciamento de features, também proporcionou uma infraestrutura robusta, eficiente e mitigou problemas de latência anteriormente enfrentados na detecção e combate à fraudes.

Conheça outros Autores
Cada artigo é resultado da visão e expertise dos nossos autores. Veja quem contribui com nosso blog:

















